Social●●Solid
daily anonymous question site, and what I'm learning from the responses
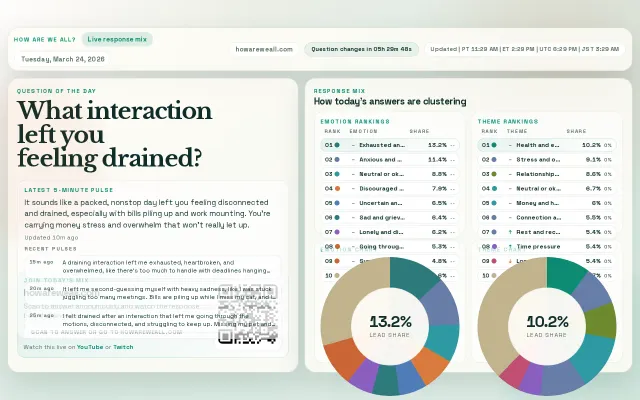
Live emotion clustering turns anonymous text answers into real-time sentiment dashboards.
CozyCrowd Pleaser
thepsychguy
104mo ago
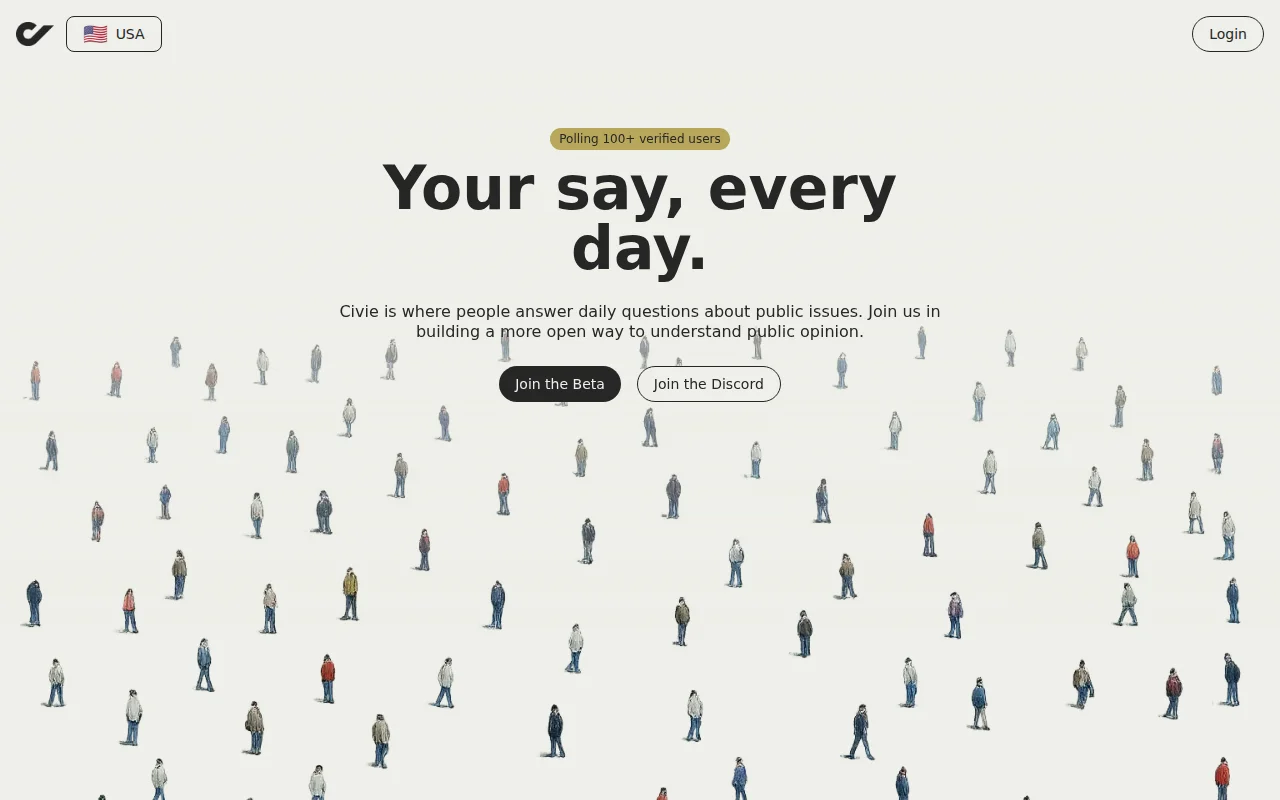
Anonymous daily civic polls, but self-selected samples and Pol.is already does this.
Civic participation enthusiasts, researchers studying public opinion, municipalities exploring engagement tools
Pol.is · Traditional polling (Pew, Gallup) · Reddit polls
I’ve been thinking a lot about barriers to civic participation. Most people don’t show up to town halls. They don’t respond to traditional surveys. And a lot of online political spaces feel loud, adversarial, or exhausting.
So I started wondering what happens if you make participation radically lightweight.
That’s where Civie comes in.
Each day you answer one to three short civic questions. It takes under a minute. Responses are anonymous. Results are shown only in aggregate. Over time, those responses accumulate into an open dataset anyone can explore.
This isn’t scientific polling, and it’s not pretending to be. The samples are self selected and nuance gets flattened. That’s an intentional tradeoff. The bet is that if participation is fast, anonymous, and recurring, more people might actually show up.
Civie is built around a few core pillars. Lower the barrier to participation. Make it safe to answer honestly. Keep the results transparent and open. And allow signal to emerge both from individual questions and from patterns over time.
I’d really value feedback on the core concept. Does a daily cadence make sense? Is anonymity enough to meaningfully lower friction? Are open aggregate results actually useful, or just interesting? What would make this something you’d return to?
If you’re curious, you can join the beta waitlist at civie.org. I’m onboarding early users in small batches and would love thoughtful testers, skeptics, and critics.
Any level of feedback and discussion welcome. Thanks!
--
A few implementation details
Civie is currently built with Next.js on the frontend and Firebase (Auth + Firestore) on the backend. It’s deployed on Vercel. The data model is intentionally simple: questions are versioned objects, and responses are stored as structured documents tied to a question ID and timestamp.
On anonymity: responses are not publicly tied to user profiles. There are no public accounts, no comment threads, and no way to see how an individual answered. The system stores responses separately from any identifying information, and aggregation happens at the query layer before display. The UI only ever exposes aggregate counts and distributions.
On identity verification: participation can require account creation to limit spam and abuse. Verification status (for example, SMS verification or identity verification via a third-party provider) is stored separately from response data. The system tracks whether a response came from a verified participant, but does not attach identity to the answer itself.
Live emotion clustering turns anonymous text answers into real-time sentiment dashboards.
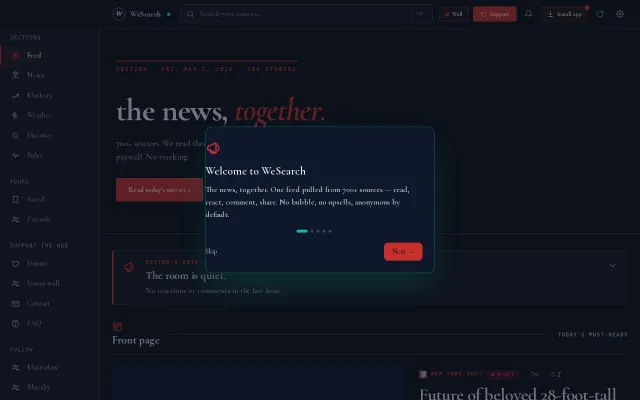
Another anti-algorithm news reader in a sea of Flipboard and Ground News clones.
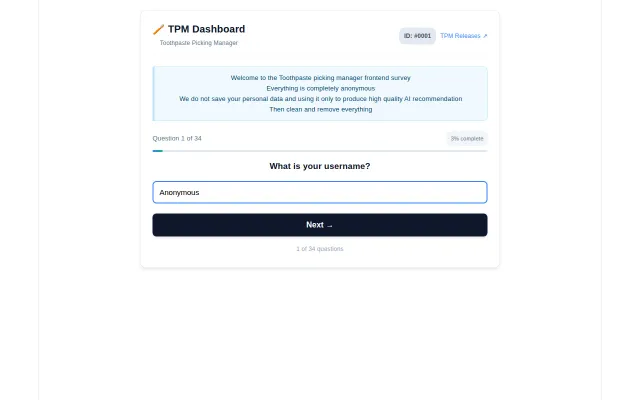
Single-gimmick survey a spreadsheet could replicate with no real technology.
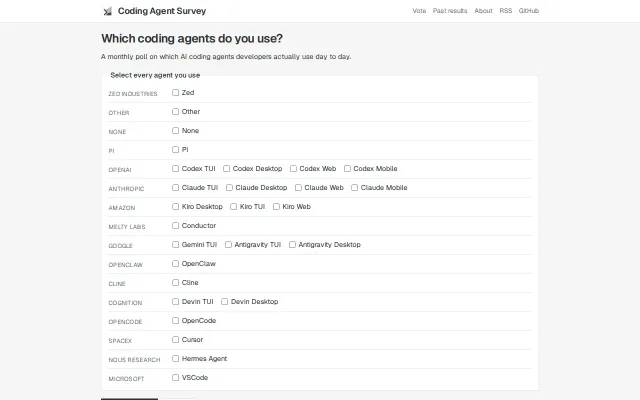
Monthly survey tracking AI coding agent adoption with no actual tool built.
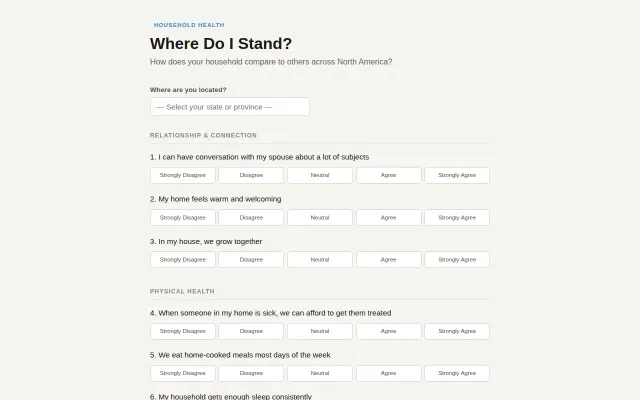
Simple household survey with local-only storage and math puzzle gate.
Word-tree aggregation for audience Q&A, but only 2 topics with 7 total contributions visible.