Data●●Solid
Bit-exact Elixir port of UltraLogLog (Ertl, VLDB 2024)
25% leaner than HyperLogLog with bit-exact validation against the Hash4j reference.
Big BrainNiche Gem
alessio66
1019d ago

Clever ML+hardware co-design, but a blog post without open-source code, benchmarks, or deployment examples.
FPGA engineers, satellite/drone firmware developers optimizing for power and area constraints
Winograd convolutions · Low-rank matrix factorization (general technique) · FPGA kernel optimization libraries
25% leaner than HyperLogLog with bit-exact validation against the Hash4j reference.
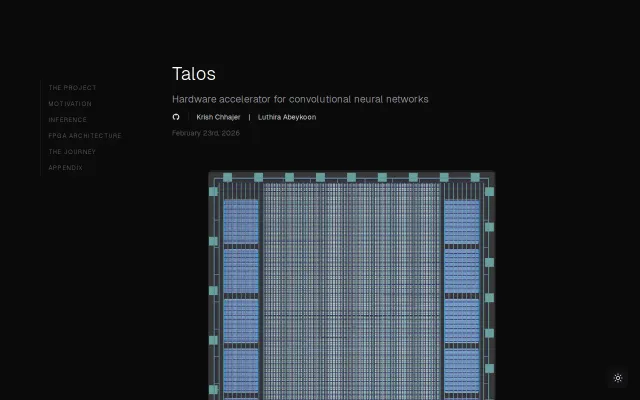
CNN inference fully hardcoded as silicon logic, not software optimized for hardware.
Strips away PyTorch flexibility entirely; full CNN inference as deterministic hardware logic in SystemVerilog.
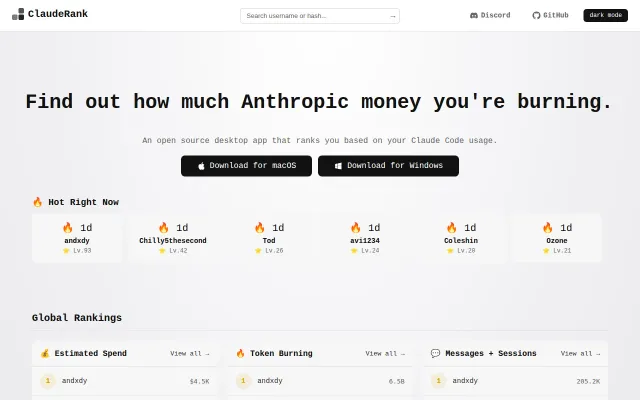
Leaderboard for Claude Code usage that tracks your token burn.
The UI pairs a live 'tokens shipped' counter with per-user leaderboards and cache-efficiency stats — exactly the kind of telemetry a team would want to monitor cost and behavior. Code hints (redis.zrevrank, OTEL_RESOURCE_ATTRIBUTES, db.execute and a mix of Rust + JS) show it's built from real infra primitives rather than a mock. It's a tidy, pragmatic tool for Claude users, but the idea is familiar and it needs clearer privacy/consent handling before I'd recommend it broadly.
Anti-engagement design actually deletes the feed instead of gamifying it.