Developer Tools●●●Banger
Colnade – Type-Safe DataFrames for Python
Type-safe DataFrames without plugins: catch column typos in your editor, not production.
Big BrainSolve My ProblemWizardry
jwde
315mo ago
🦦 Pandas-style DataFrame library for Go — fluent API for filtering, grouping, sorting, and statistical analysis with type-safe operations and zero-copy typed slice access.
Pandas API in pure Go, but Polars and DuckDB already own this space.
Go developers doing data analysis, ETL, and analytics without Python/JVM dependencies.
Polars · DuckDB · Gota (Go DataFrame library)
GitHub: https://github.com/datumbrain/otters
I started this because most Go DataFrame libraries I tried were either abandoned, hard to use, or didn’t feel idiomatic to Go. I wanted something that:
• works fully in-process (no cluster / Spark dependency)
• uses native Go types instead of generic interface blobs
• supports expressive chained operations
• stays readable and explicit like Go code should
• can scale to large datasets in memory pipelines
Design goals were:
• simplicity over magic
• type safety over dynamic guessing
• composability for real data pipelines
It’s still early but functional, and I’d genuinely appreciate feedback from people who’ve built data tooling or worked on columnar engines / query planners. Critiques welcome — API design, performance, architecture, anything.
Type-safe DataFrames without plugins: catch column typos in your editor, not production.
Compiles pandas logic to TorchScript, then runs C++-only inference—eliminates Python runtime bottleneck for quant workflows.
Lint-time DataFrame checking when Pandera only validates at runtime.
Yet another Polars competitor, but this one wraps existing C++ code.
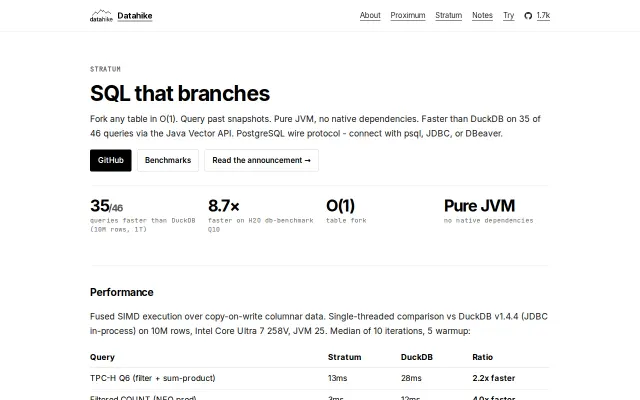
Java Vector API beats DuckDB on 35/46 queries; O(1) table branching via structural sharing.
Pure Swift Argon2 avoids FFI, but lacks libsodium's battle-tested audit history.