Productivity●●Solid
Focus Warden – Block sites, set time limits, and micro-learn
Micro-learning unlock reframes distraction recovery productively, not just punitively.
Solve My ProblemDark Horse
EdwardK1
104mo ago
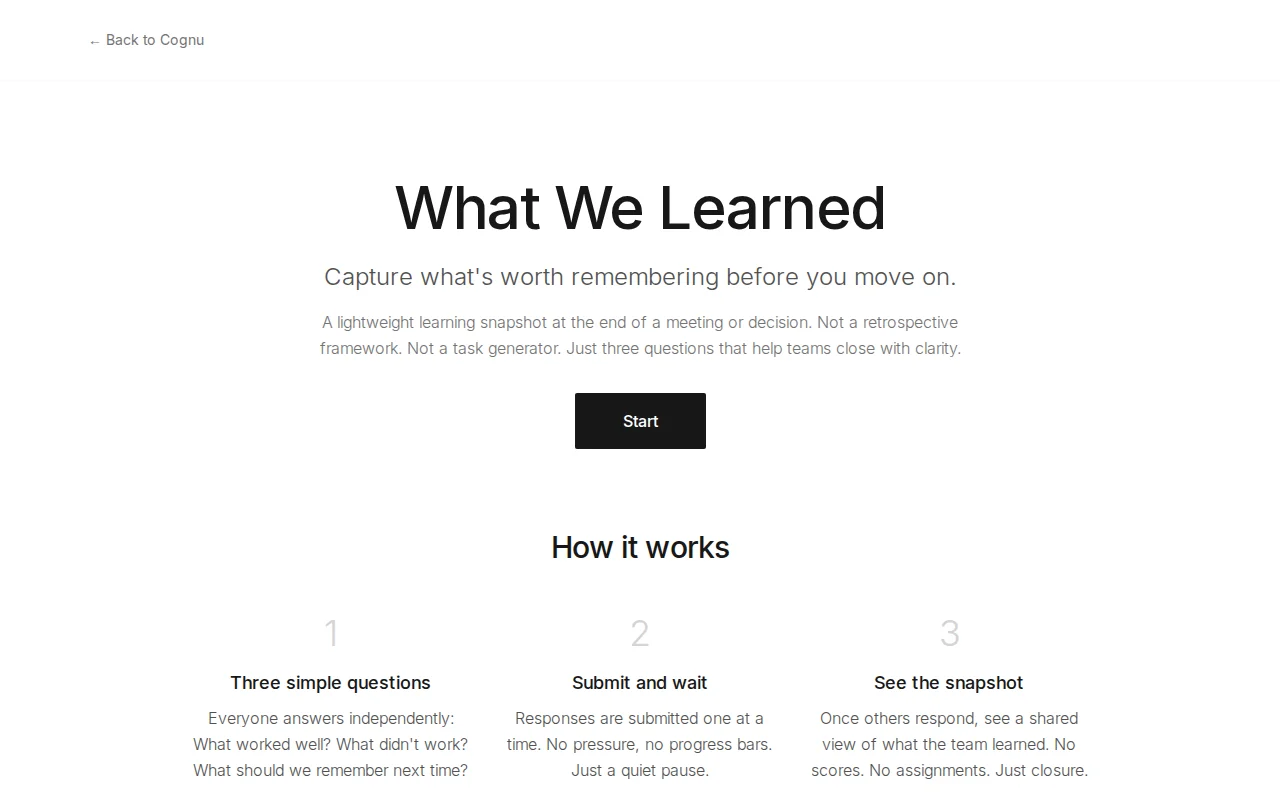
It forces a quiet, useful pause: everyone answers three independent prompts (what worked / what didn't / what to remember) with no accounts, then you get a shared snapshot. Smart behavioral design — avoids first-writer priming and heavyweight retros — but adoption will hinge on integrations (Slack/CSV/export) and a simple habit-building flow.
Product managers, engineering teams, workshop facilitators and anyone who runs meetings and wants quick shared learning without overhead
It wasn’t that people weren’t paying attention. We just never paused long enough to capture what we learned while it was still fresh. Retros felt too heavy for everyday decisions. Shared docs didn’t really solve it — the first person to write would shape everyone else’s answer.
So I made something intentionally small.
At the end of a meeting, it asks three questions: – What worked? – What didn’t? – What should we remember next time?
Everyone answers independently, then you see a shared snapshot. No accounts, no scoring, no task generation. It’s just a short pause before moving on. Curious if others have run into this, or solved it differently.
Micro-learning unlock reframes distraction recovery productively, not just punitively.
Yet another AI course generator when Khanmigo and countless tutors already exist.
It flips the doomscroll mechanic into a micro-learning loop with swipeable "Intel Cards" and a fun unlockable retro "Intel Archive" terminal for deep dives — neat UX framing. The no-login PWA and terminal aesthetic are clever hooks, but the concept is familiar; success will depend on content depth, retention mechanics (spaced repetition/personalization), and how sticky the loop actually is.
Micro-challenge approach beats passive video tutorials for learning p5.js.
Lightweight questioning framework, but MECE checklists and interview guides already exist.
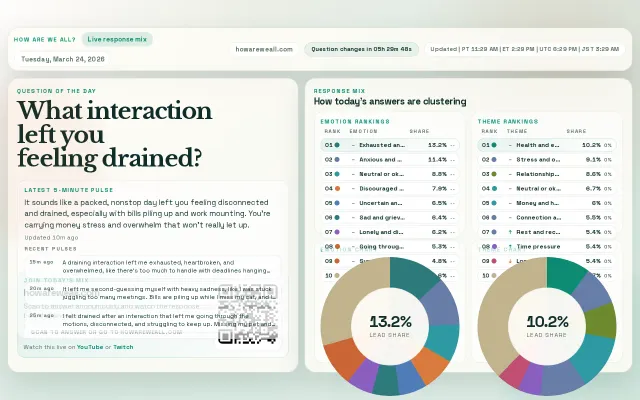
Live emotion clustering turns anonymous text answers into real-time sentiment dashboards.