Developer Tools●Mid
DumpCleaner – Native macOS/iPadOS app to filter SQL dumps
SQL dump cleaner that beats sed/grep — but the market for $30 niche tools is microscopic.
Eye CandySolve My Problem
marcelglaeser
115mo ago
A command-line tool to extract plain text from Wikipedia dumps with category and section filtering
Category-aware Wikipedia text extraction with 20-year maintenance history and parallel M4 speed.
Corpus linguists, NLP researchers, Wikipedia data miners
mwclient · pywikibot · Mediawiki API
- Auto-download dumps by language code (350+ languages) - Extract specific articles by title without downloading the full dump - Extract articles from a Wikipedia category with subcategory recursion - Extract specific sections by name with alias matching (e.g., "Plot" also matches "Synopsis") - Template expansion (dates, coordinates, unit conversions → readable text) - Content type markers ([MATH], [TABLE], etc.) instead of silent removal - Category metadata preserved in output - JSON/JSONL output - Parallel processing (English Wikipedia 24 GB dump: ~2 hours on Apple M4) - Written in Ruby.
SQL dump cleaner that beats sed/grep — but the market for $30 niche tools is microscopic.
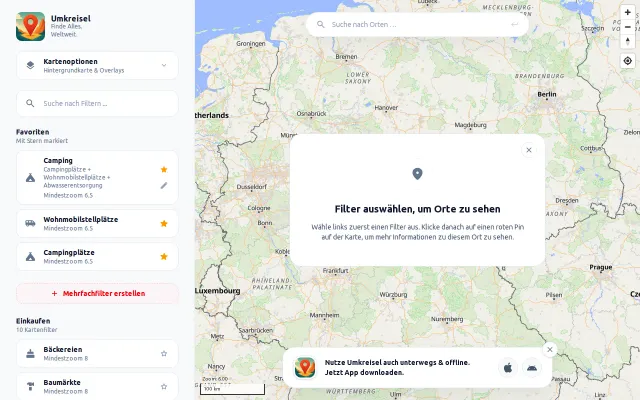
Aggregates niche filters like dog poop bags and glass recycling on one map.
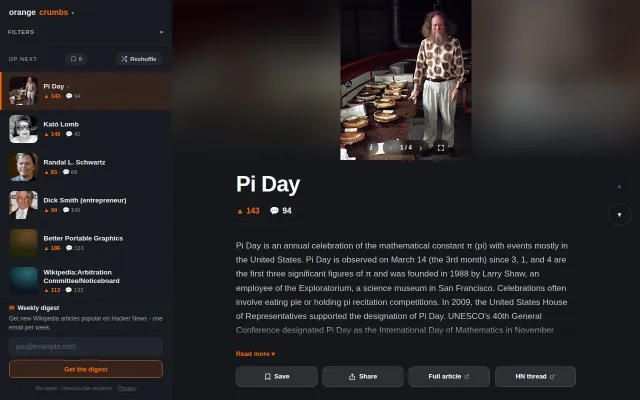
Clever HN-Wikipedia correlation that surfaces context behind trending discussions.
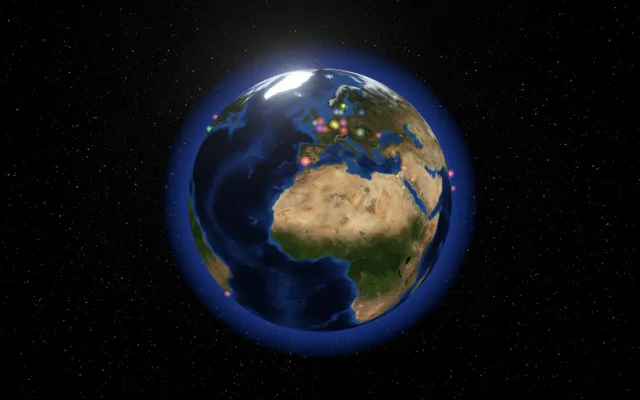
Cinematic 3D globe visualizing Wikipedia edits, but lacks deep data interaction tools.
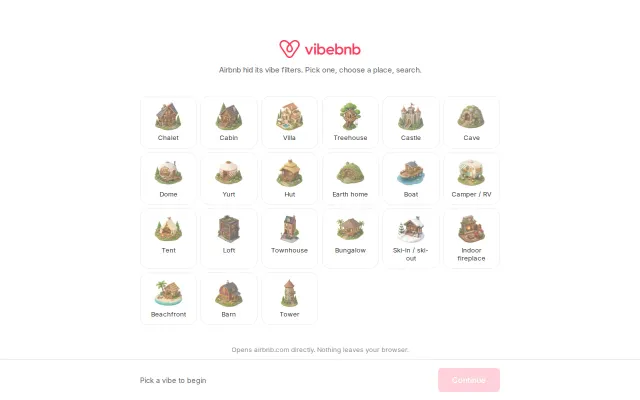
Recovered Airbnb's hidden GraphQL category params when they removed the UI.
Useful directory for MCP discovery, but it's just a curated list with search — no novel tech.