Infrastructure●Mid
Searchable JSON compression (offline demo and DD evidence and BYOD kit)
Searchable JSON compression with page-level access is clever, but it's a pre-revenue tech asset, not a working product.
Big BrainBold Bet
Tetsuro
103mo ago
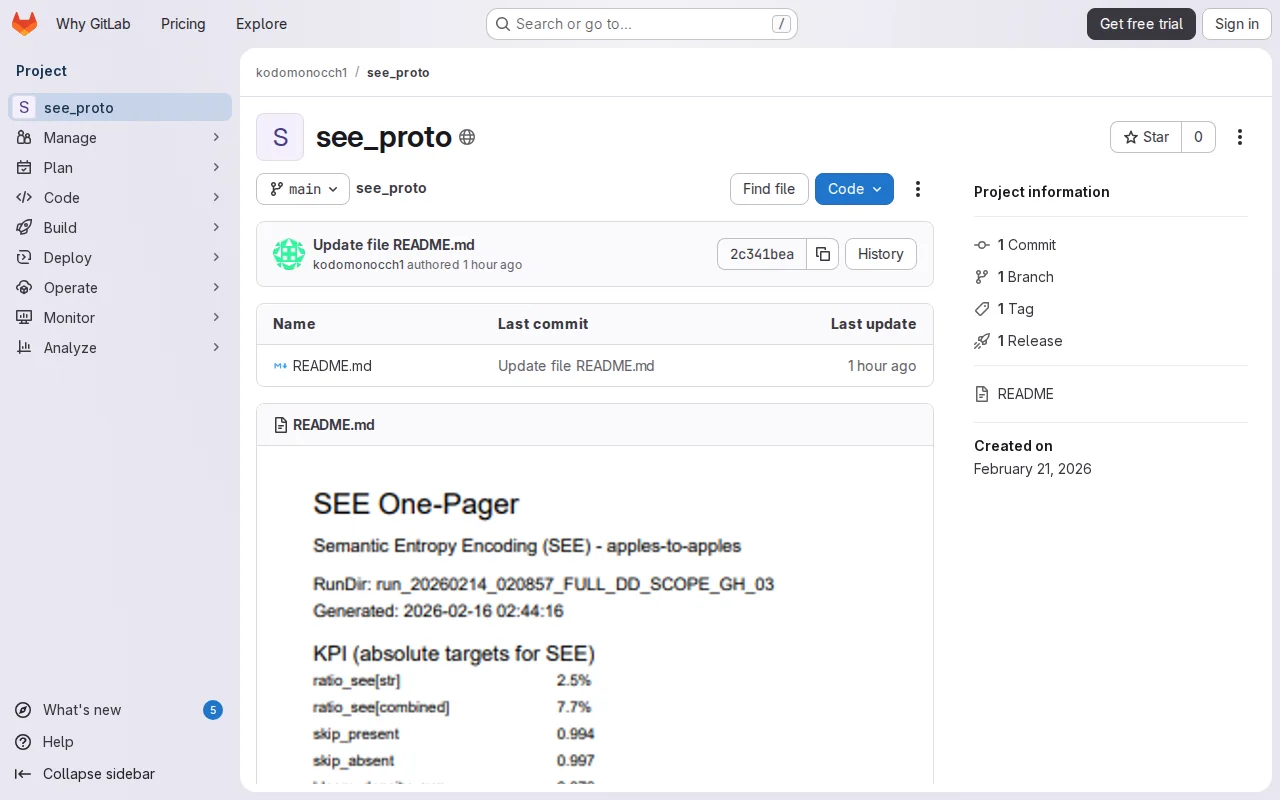
Schema-aware JSON compression stays searchable; reaches 7.7% vs Zstd's 13.7%.
Data engineers, observability teams, storage optimization specialists
Zstandard (Zstd) · Apache Arrow · Protocol Buffers
I just published a proof-first evaluation release:
Offline DEMO ZIP (~10 min): prints compression ratios + skip rates + lookup latency (p50/p95/p99)
DD pack: audit/repro evidence (decode mismatch=0, extended mismatch=0, audit PASS)
Latest release: https://gitlab.com/kodomonocch1/see_proto/-/releases
Direct DEMO ZIP: https://gitlab.com/api/v4/projects/79686944/packages/generic...
OnePager is included in the release assets.
I’d love feedback on:
what workloads you’d try this on, and
what integration path would make this compelling vs Zstd + external indexing.
Searchable JSON compression with page-level access is clever, but it's a pre-revenue tech asset, not a working product.
Beats Zstd-19 on size, keeps JSON queryable without external indexes.
Searchable JSON compression at 7.7% with 0.085ms random lookups; skips 99% of pages.
ML classifier detects text formats automatically, but CloudConvert already does 50+ formats.
32x embedding compression without calibration beats product quantization's training overhead.
Rust CLI with Kotlin/Python bindings and multi-codec support, but ImageMagick already dominates.