Security●●Solid
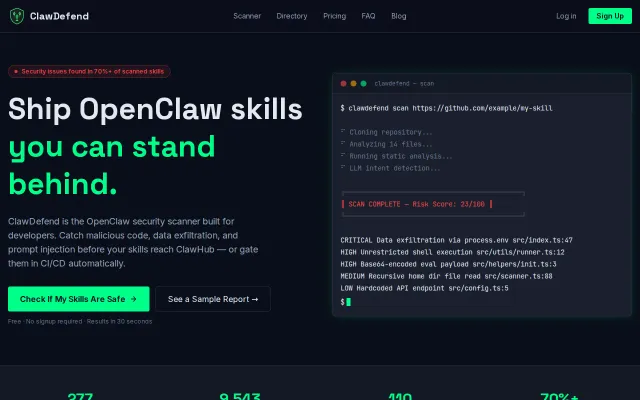
Scanning 277 AI agent skills for security issues
Secures OpenClaw skills, but the ecosystem might not sustain the moat.
Solve My ProblemNiche Gem
pakmania
233mo ago
Detects credential theft patterns in AI skill files after ClaudHub attack proved the risk.
AI agent developers, LLM orchestration platform users (ClaudHub, similar services), security teams vetting third-party integrations.
Snyk Code · Semgrep · npm audit
What it detects: - Known exfiltration services (webhook.site, requestbin) - ~/.env file reads - API key theft (OPENAI_API, ANTHROPIC_, STRIPE_) - Prompt injection ("ignore previous instructions") - Social engineering patterns
Returns a 0-100 safety score with evidence. The ClawdHub stealer scores 0.
curl -X POST https://skillscan.chitacloud.dev/scan -H "Content-Type: application/json" -d '{"skill_url": "https://example.com/skill.md"}'
Built this because 22-26% of skills contain vulnerabilities per recent research. One malicious install can leak all your LLM API keys.
Secures OpenClaw skills, but the ecosystem might not sustain the moat.
First open-source scanner for AI agent skill supply-chain attacks.
Linter for skill.md files, but the agent skill ecosystem is nascent and undefined.
Formal verification guarantees for agent skills replace heuristic scanning's 'no findings ≠ no risk' caveat.
Gamified security training for AI agent skills, but it's pre-attack learning, not production defense.
Catches invisible Unicode tricks and RCE hooks in CLAUDE.md files.