Developer Tools○Pass
Linux installer .exe without pendrives (secure-boot compatible)
Selling alpha software that admits it can permanently damage your hardware.
Bold Bet
arusekk
511mo ago
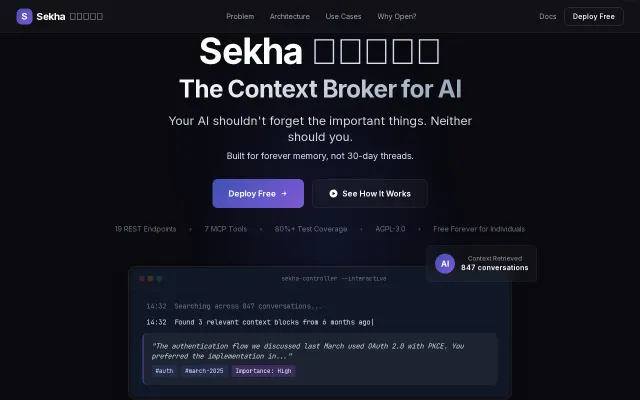
File Hunter — catalog, deduplicate, and consolidate your archive storage
Catalog millions of files once, browse offline forever—three-tier hashing kills duplicates across terabytes.
Power users managing large archives, media professionals, anyone with drawers of USB drives
Synology File Station (but offline + deduplication focus) · Tagsistant (file tagging, but no offline catalog)
File Hunter is a self-hosted, web-based file manager. You point it at any folder — USB drive, network share, DVD — and it catalogs everything into SQLite. When you unplug the drive, the full catalog stays. You can browse, search, and review files on storage that isn't connected.
The other thing it does well is deduplication. A three-tier hashing strategy (file size → xxHash64 partial → SHA-256 full) finds exact duplicates across all your locations with minimal I/O. Then you can consolidate: keep one copy, stub the rest, full audit trail.
Some numbers: I run it on a catalog of ~7 million files across 9.6 TB and 10 locations. The UI stays responsive during scans.
Tech: Python, Starlette, uvicorn, SQLite (WAL mode), vanilla JavaScript. No frameworks, no build step, no npm. One curl command to install:
curl -fsSL https://filehunter.zenlogic.uk/install | bash
It's MIT-licensed and free. There's a paid Pro tier that adds remote agents (scan machines across the network into one catalog), but everything on the GitHub page is the free version and will stay that way.Website: https://filehunter.zenlogic.uk GitHub: https://github.com/zen-logic/file-hunter
Happy to answer questions about the architecture, the dedup strategy, or anything else.Selling alpha software that admits it can permanently damage your hardware.
USB-less Linux installer when Tunic already does this more maturely.
Portable memory for multi-LLM workflows, but Mem0 and MemGPT already solve this.
MCP integration exposes infrastructure as AI tools — clever, but Coolify exists.
Lightweight self-hosted alternative to Backstage for teams drowning in Swagger files.
GUI for TCG self-encrypting drives with pre-boot auth, finally usable.