Other●●Solid

The Crawl Times – Newspaper-style front pages for tech news sites
Cloudflare /crawl API powers nostalgic newspaper layouts for Hacker News and friends.
Eye CandyCozy
g_br_l
502mo ago
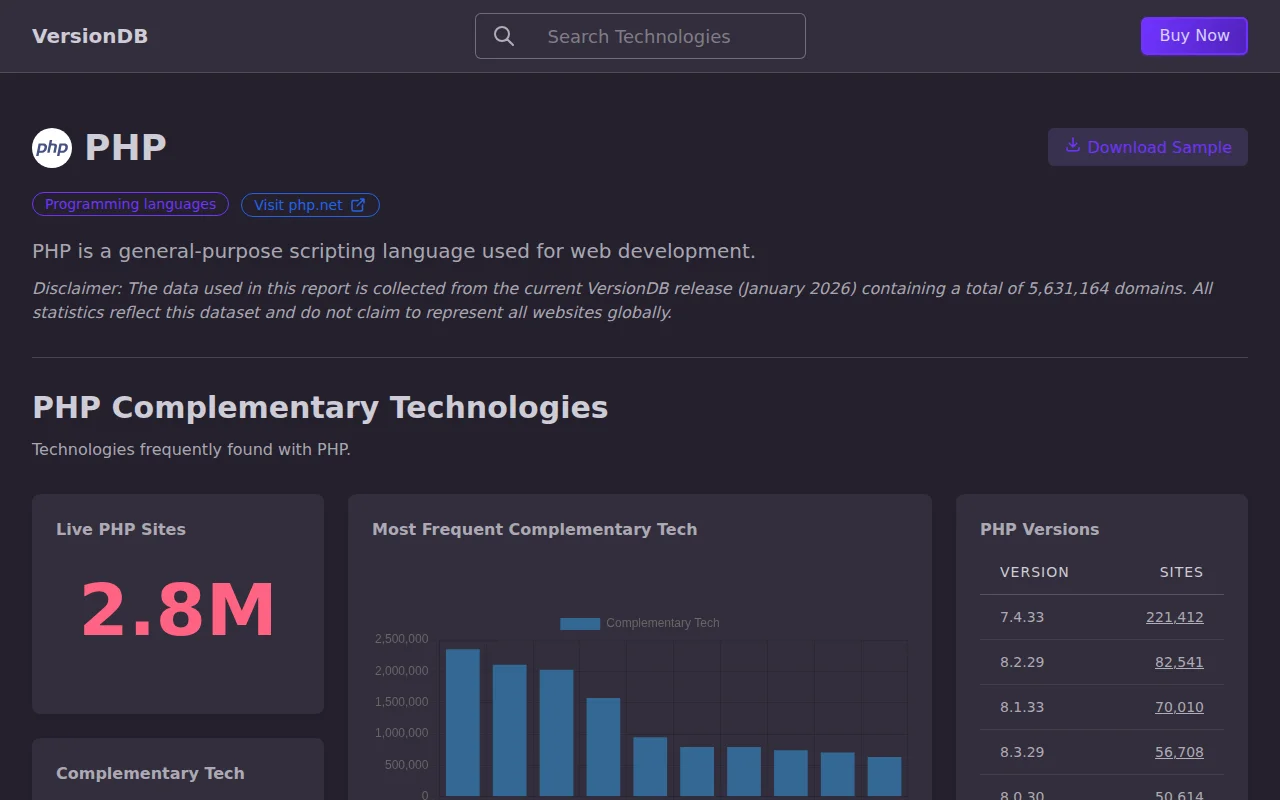
Crawled 5.6M sites, but tech stack distribution dashboards already exist (BuiltWith, Wappalyzer).
Web developers, enterprise architects, and tech talent managers researching stack prevalence
BuiltWith · Wappalyzer · Similarweb
Cloudflare /crawl API powers nostalgic newspaper layouts for Hacker News and friends.
No-browser docs crawler using defuddle when Firecrawl and JinaAI already exist.
Playwright-driven crawling + deterministic token extraction plus an LLM for semantic labeling is a clever pipeline — it doesn’t just scrape CSS, it produces an AI-optimized .design-memory folder with tokens, component recipes, and multi-page merge/diff capabilities. Expect variable fidelity on highly dynamic or framework-heavy sites since the approach depends on selector heuristics and an API key, but the CLI commands (learn, install, diff) and docs show this is more than a research sketch.
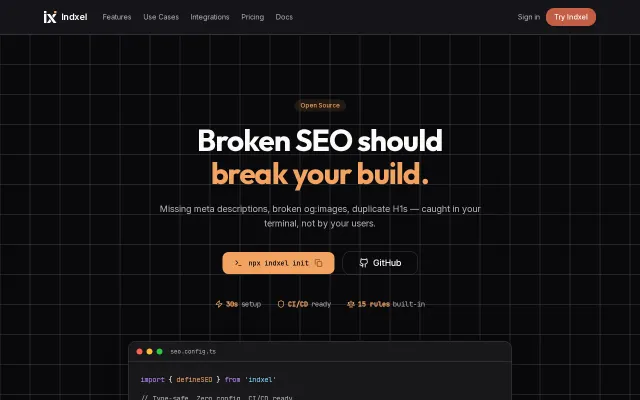
It actually treats meta and OG tags like first-class testable artifacts: one command scaffolds seo.config.ts, sitemap and OG routes, another crawls and scores pages, and indxel check --ci will fail your build on regressions — plus deploy diffs so you see exactly what changed. The combo of Type-safe config, auto-generated JSON-LD, auto-indexation retries and an AI audit option (Claude) feels thoughtful and developer-oriented; this isn't just prettier Lighthouse output, it's CI-friendly SEO infra.
HN mirror for Europe, but aggregation without new insights doesn't create stickiness.
Docs chatbot for static sites—but Mendable, Librarian, and ChatBot already own this space.