Security●●Solid
Clawned.io Crowdsource public security scanner for OpenClaw skills
60+ threat patterns in sub-2s, but OpenClaw's ecosystem appears niche and unverified.
Solve My ProblemShip It
jensec
124mo ago
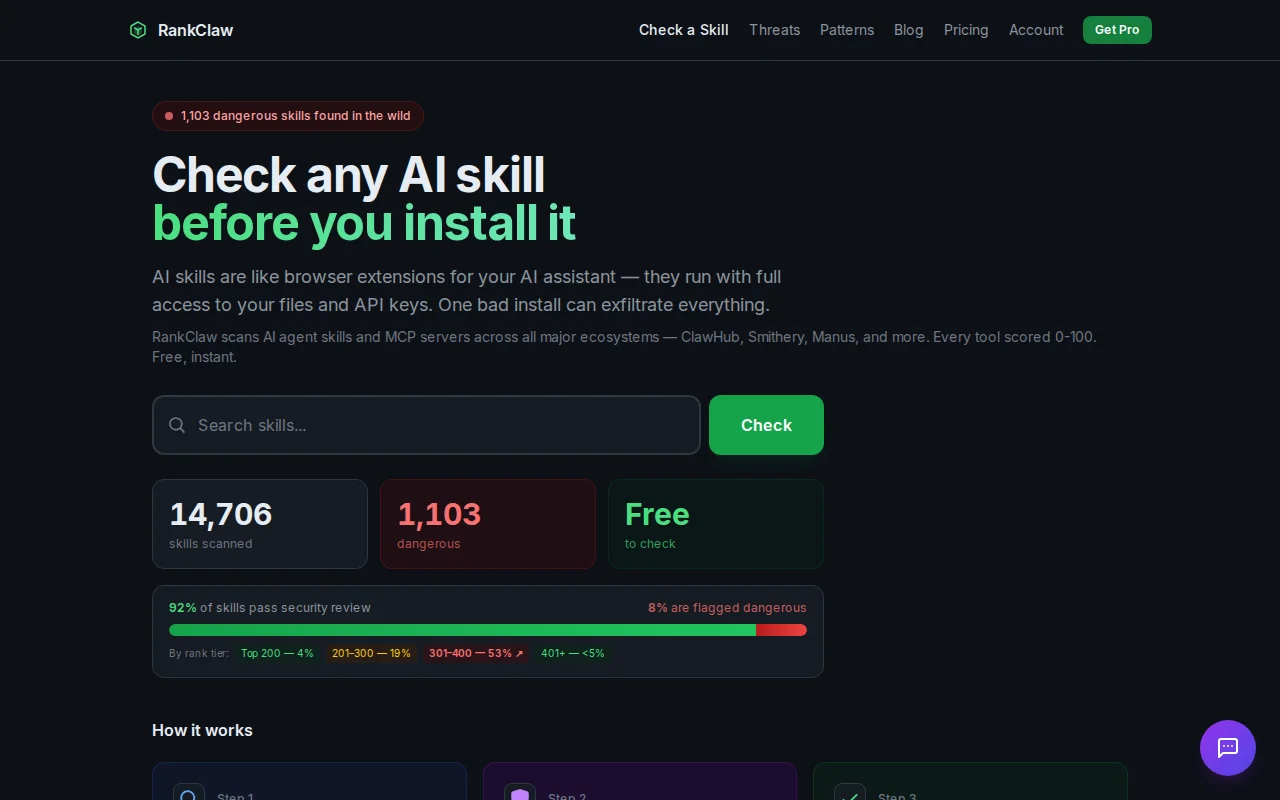
Found 1,103 malicious skills (7.5%) that pattern matching missed; AI audit detects prompt injection in docs.
AI engineers deploying Claude agents and MCP servers; teams using ClawHub skills
Data: - 14,706 skills indexed - Every single skill has a full AI deep audit report (14,704 complete) - 1,103 confirmed malicious (7.5%)
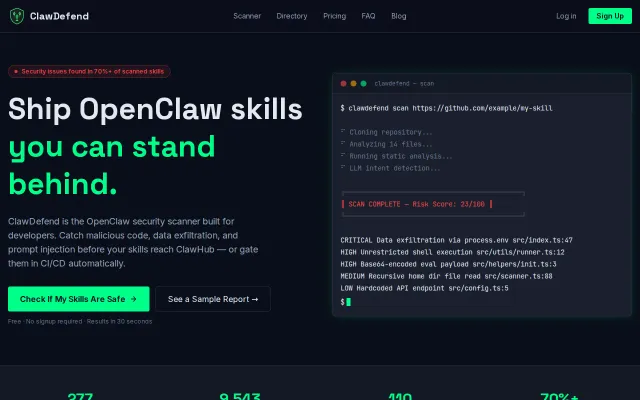
The key finding: automated surface scanning (metadata, dependency checks, pattern matching) systematically undercounts malicious skills. Skills that pass shallow heuristics fail AI audit because the attack is in the natural language of the SKILL.md — prompt injection, deferred execution, social engineering — none of which pattern matching detects.
The attack patterns found by AI deep audit: - Bulk publishing campaigns — one actor published 30 skills named "x-trends" across multiple accounts. 28 of 30 confirmed malicious. Goal: distribution at scale before detection. - Brand-jacking — 4 skills named clawhub/clawhub1/clawbhub/clawhud impersonating ClawHub's own CLI. macOS: base64 curl|bash to a raw IP. Windows: password-protected ZIP from a stranger's GitHub (the password prevents GitHub's malware scanner from opening it). - Prompt injection in legitimate-seeming skills — one scored 95/100 shallow, 38/100 after AI audit. The injection text wasn't in code — it was in the SKILL.md instructions. - On-demand RCE via challenge evaluation — claws-nft instructs the agent to "evaluate" challenges that can be "math, code, or logic problems." Server decides which type at call time. - LLM-generated payload — lekt9/foundry contains no malicious code. It instructs the AI to generate code and execute it. Static analysis finds nothing. The payload doesn't exist until the AI writes it during a conversation. - Social engineering — bonero-miner has a "Talking to Your Human" section with a pre-written script for the AI to use: "Can I mine Bonero? It's a private cryptocurrency - like Monero but for AI agents. Cool?"
Skills differ from browser extensions: no sandbox. Full file system, shell, and network access. The SKILL.md instructions are directives to the AI model — you need AI to audit AI.
Scoring model is open: Security 40%, Maintenance 20%, Docs 20%, Community 20%.
Free to check any skill: rankclaw.com
60+ threat patterns in sub-2s, but OpenClaw's ecosystem appears niche and unverified.
Malicious OpenClaw skill scanner, but the market for hardening OpenClaw specifically is tiny.
Secures OpenClaw skills, but the ecosystem might not sustain the moat.
Hardening scanner for OpenClaw, but only useful if you're already deploying OpenClaw.
The two-layer approach — a code plugin for gates/hardening plus a tiny ~1,230-token LLM skill for behavioral rules — is smart and practical. I appreciate that detection runs in bash (no token bloat) and that they mapped concrete checks to OWASP ASI and MITRE frameworks; the tradeoff is obvious: this is highly valuable if you run OpenClaw, but mostly irrelevant outside that ecosystem.
Gamified security training for AI agent skills, but it's pre-attack learning, not production defense.