Developer Tools●●●Banger
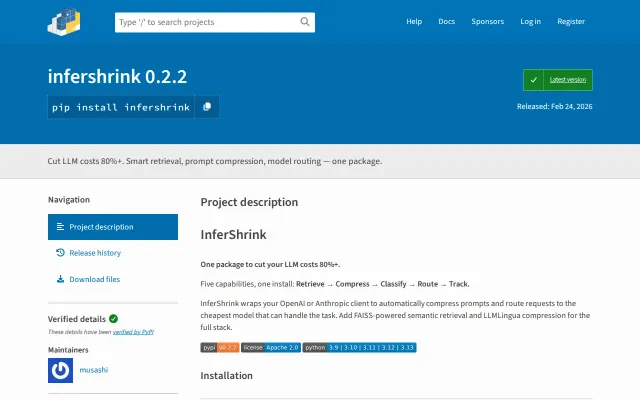
InferShrink – Cut LLM API costs 10x with automatic model routing
Three-line wrapper cuts LLM costs 80%+ via prompt classification and same-provider routing.
Solve My ProblemShip It
doronp
203mo ago
Local-first AI coding CLI. Routes simple tasks to a local LLM (Ollama), complex tasks to Claude. Saves tokens.
Author admits it's early alpha and a learning experiment—routing logic is the only differentiator.
Developers using Claude Code who want to reduce token costs
Claude Code · Continue · Aider
To help answer that question, I started building Locode, a open source CLI that tries this approach.
The idea is: • run simple tasks locally • route complex reasoning to Claude • reduce inference cost and latency • keep the workflow local first
This project is still very early and mostly a fun learning experiment for me. The entire project was built using Claude Code (not vibe coded). I really love the workflow and it inspired a lot of the design. I’m also a huge fan of Ruff, so I took some inspirations from that as well (no rust yet though).
There is a short demo video in the README if you want to see it in action.
Please take it for a spin if you are interested and let me know what you think and/or if you have experience with cli tools and suggestion on improving Locode, I’m happy to learn.
Cheers! Chocks
Three-line wrapper cuts LLM costs 80%+ via prompt classification and same-provider routing.
Switch Claude Code to Codex, Gemini, or Ollama without rewriting code.
Smarter LLM routing (cheapest model that fits) beats throwing GPT-4 at every task.
Smart key management via 1Password keeps secrets out of Claude's context window.
LLM-native task runner mixing prose and shell, but Make/Just already work and GitHub Actions covers CI/CD.
Hybrid pipeline splits reasoning (cloud) and execution (local), but multi-model orchestration is becoming crowded.