Developer Tools●●Solid
Pluckr – LLM-powered HTML scraper that caches selectors and auto-heals
LLM-generated selector caching beats manual scraping, but Jina AI and Beautiful Soup handle this cheaper.
Big BrainSolve My Problem
pankaj3112
113mo ago
CSS flex ordering makes textContent return garbage while visual rendering stays perfect.
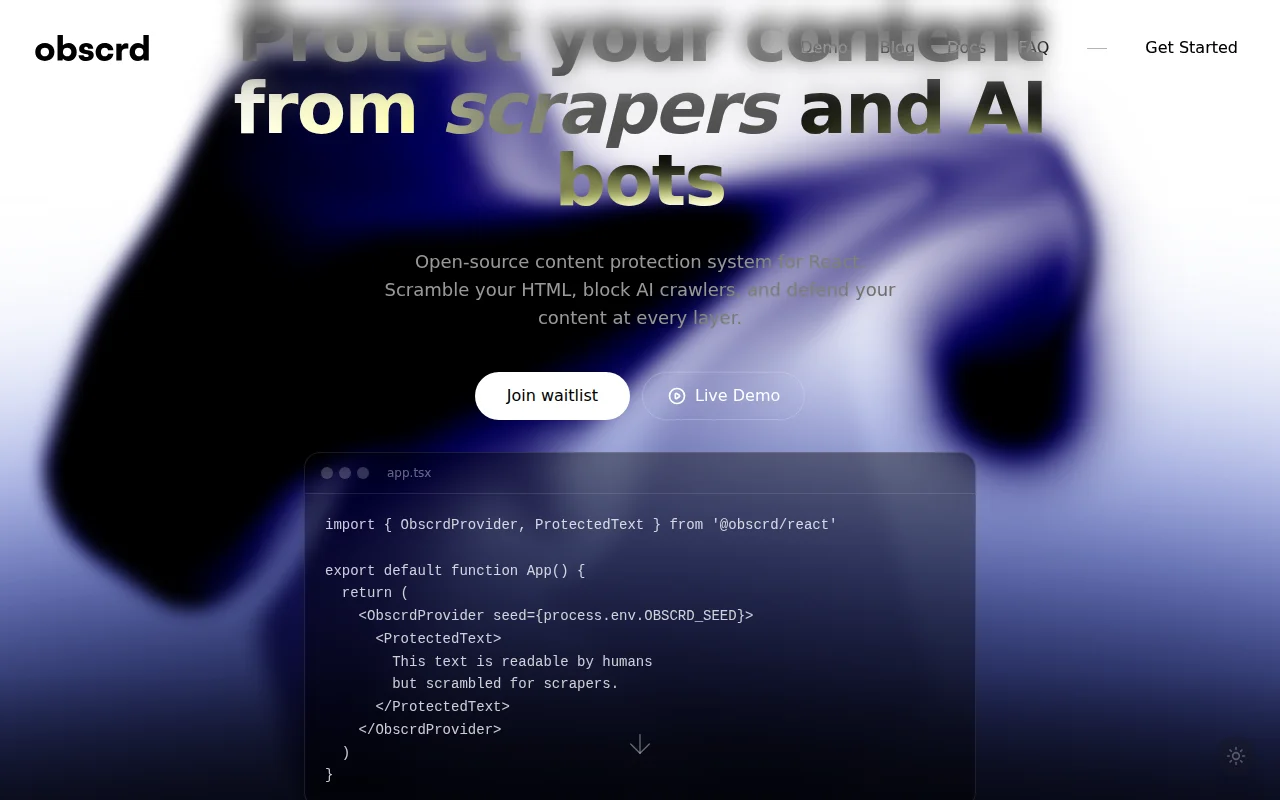
Content creators and publishers protecting against AI crawlers
CopyProtect · Digiprove
The core trick: shuffle characters and words in your HTML using a seed, then use CSS (flexbox order, direction: rtl, unicode-bidi) to put them back visually. Browser renders perfectly. textContent returns garbage.
On top of that: email/phone RTL obfuscation with decoy characters, AI honeypots that inject prompt instructions into LLM scrapers, clipboard interception, canvas-based image rendering (no img src in DOM), robots.txt blocking 30+ AI crawlers, and forensic breadcrumbs to prove content theft.
What it doesn't stop: headless browsers that execute CSS, screenshot+OCR, or anyone determined enough to reverse-engineer the ordering. I put this in the README's threat model because I'd rather say it myself than have someone else say it for me. The realistic goal is raising the cost of scraping -- most bots use simple HTTP requests, and we make that useless.
TypeScript, Bun, tsup, React 18+. 162 tests. MIT licensed. Nothing to sell -- the SDK is free and complete.
Best way to understand it: open DevTools on the site and inspect the text.
GitHub: https://github.com/obscrd/obscrd
LLM-generated selector caching beats manual scraping, but Jina AI and Beautiful Soup handle this cheaper.
LLM infers selectors once, Go extracts 10k rows—smart AI-for-intelligence architecture.
PicoCSS aesthetics at 3.8 KB with fewer variables and Open Props integration.
Embeds DOM selectors in markdown comments so scrapers don't need LLM on every run.
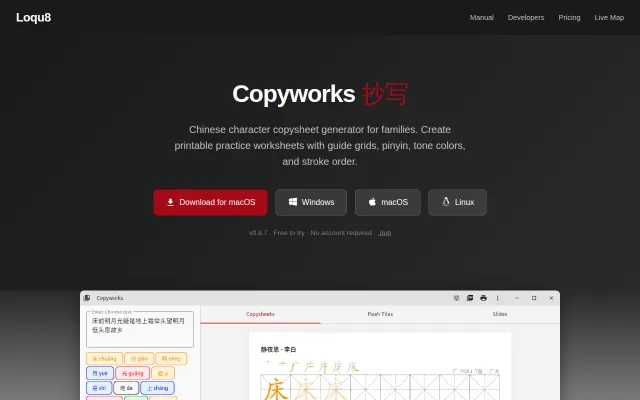
Tone-colored characters + offline desktop app fills a real gap for home Chinese learning.
CSS-only Flappy Bird is a fun five-minute novelty with no practical use beyond the demo itself.