Security●●●Banger
AgentThreatBench – Benchmark for AI Agent Memory Security
First OWASP-backed security layer for ASI06 memory poisoning in agentic AI.
Big BrainSolve My Problem
vgudur297
2014d ago
8-layer defense-in-depth security for agentic AI. Covers OWASP ASI Top 10 across ingestion, storage, context, planning, execution, output, inter-agent, and identity layers.
Eight-layer defense-in-depth for AI agents when Guardrails AI only handles inputs.
AI application developers, CTOs building agentic systems
Guardrails AI · Lakera Guard · Rebuff
So I built AgentArmor: an open-source framework that wraps any agentic architecture with 8 independent security layers, each targeting a distinct attack surface in the agent's data flow.
The 8 layers: L1 – Ingestion: prompt injection + jailbreak detection (20+ patterns, DAN, extraction attempts, Unicode steganography) L2 – Storage: AES-256-GCM encryption at rest + BLAKE3 integrity for vector DBs L3 – Context: instruction-data separation (like parameterized SQL, but for LLM context), canary tokens, prompt hardening L4 – Planning: action risk scoring (READ=1 → DELETE=7 → EXECUTE=8 → ADMIN=10), chain depth limits, bulk operation detection L5 – Execution: network egress control, per-action rate limiting, human approval gates with conditional rules L6 – Output: PII redaction via Microsoft Presidio + regex fallback L7 – Inter-agent: HMAC-SHA256 mutual auth, trust scoring, delegation depth limits, timestamp-bound replay prevention L8 – Identity: agent-native identity, JIT permissions, short-lived credentials
I tested it against all 10 OWASP ASI (Agentic Security Integrity) risks from the December 2025 spec. The red team suite is included in the repo.
Works as: (a) a Python library you wrap around tool calls, (b) a FastAPI proxy server for framework-agnostic deployment, or (c) a CLI for scanning prompts in CI.
Integrations included for: LangChain, OpenAI Agents SDK, MCP servers.
I ran it live with a local Ollama agent (qwen2:7b) – you can watch it block a `database.delete` at L8 (permission check), redact PII from file content at L6, and kill a prompt injection at L1 before it ever reaches the model.
GitHub: https://github.com/Agastya910/agentarmor PyPI: pip install agentarmor-core
Would love feedback, especially from people who have actually built production agents and hit security issues I haven't thought of.
TAGS: security, python, llm, ai, agents
First OWASP-backed security layer for ASI06 memory poisoning in agentic AI.
Eight enforced security layers for AI agents, but unclear if this beats custom middleware for most teams.
Marketing blog post for existing product, not a tool you can actually try or verify.
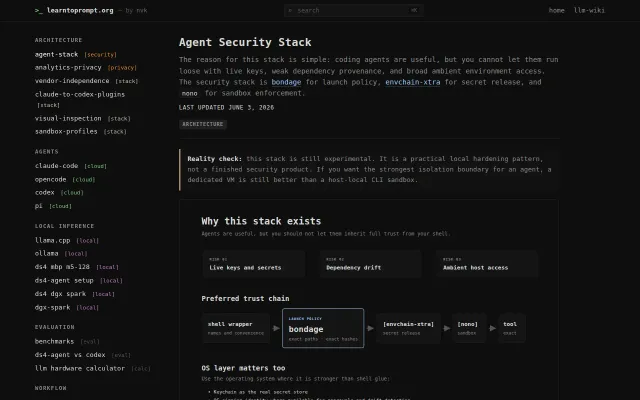
Three-layer security stack separates launch policy, secret release, and sandbox enforcement.
Single Python file adds Telegram 2FA and honeypot traps to OpenSSH.
Post-quantum crypto and ZK proofs for AI agent security when the category is still emerging.