Gaming●Mid

WordRank: A Word Frequency Game
Wordle clone that swaps spelling for linguistics, but the frequency data feels arbitrary.
Cozy
edan
1115d ago
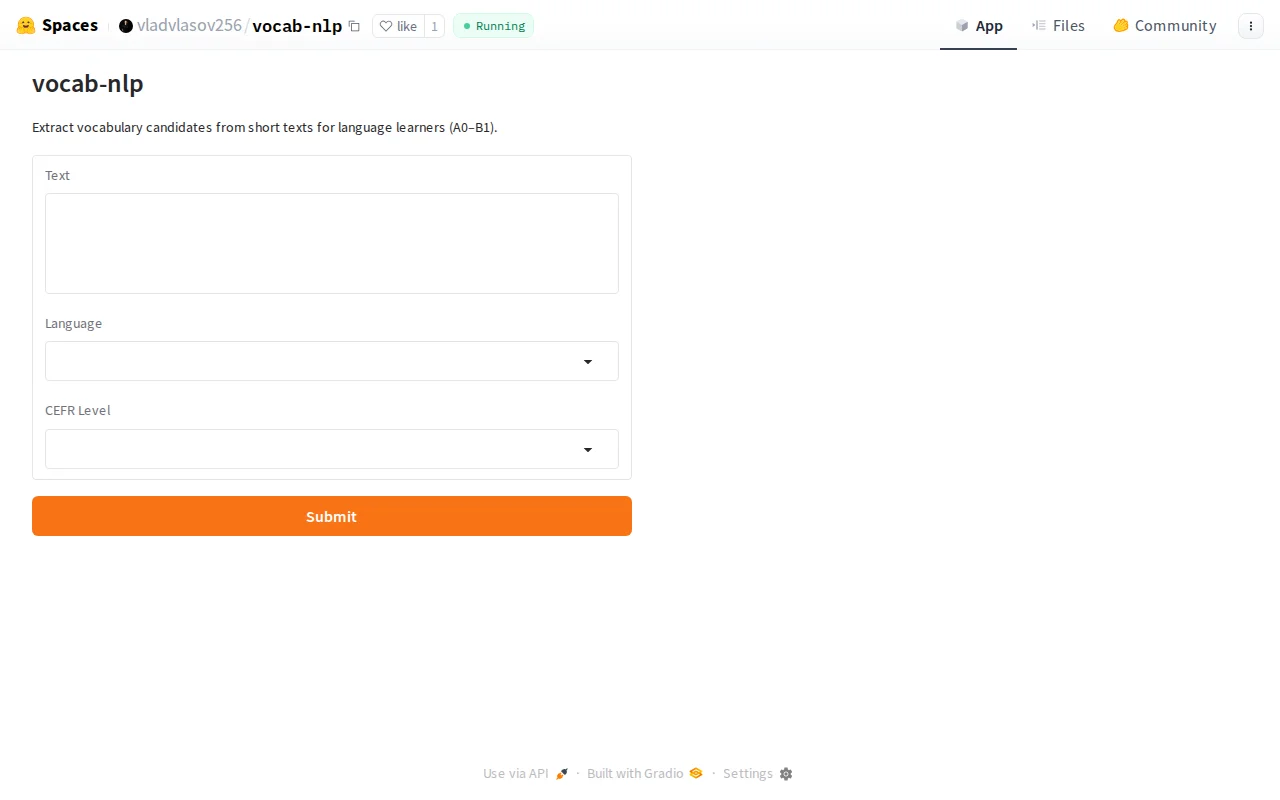
Classical NLP beats LLMs at knowing which words you don't know.
Language learners, ESL teachers, EdTech developers
Readlang · LingQ · Clozemaster
It takes a short text + learner level (A0–B1) and returns the best words to study, using Stanza for parsing and corpus frequency ranks (SUBTLEX-NL, srLex, SUBTLEX-US) for scoring. Wins at A1/A2, loses at A0 where the LLM picks more obvious words.
I also tried adding multi-word phrases (ADJ+NOUN, VERB+NOUN, phrasal verbs) backed by NPMI-scored collocation whitelists. Couldn't beat GPT there because it just "knows" which phrases matter.
For the phrase work I had to extract collocations from 100M+ OpenSubtitles lines. Published them as a free dataset: https://huggingface.co/datasets/vladvlasov256/opensubs-collo... There are 43K bigrams across English, Dutch, and Serbian.
Wordle clone that swaps spelling for linguistics, but the frequency data feels arbitrary.
Skip/watch signals rank language videos but Language Reactor and FluentU already solve this.
Crosswords + Anki is a clever combo nobody's built for vocab learning.
Desktop-first AI tutor for deliberate language practice without mobile gamification.
Duolingo leagues already do ELO-ranked language learning with bigger content libraries.
Zoom for language exchange with a built-in timer to enforce equal speaking time.