Infrastructure●●Solid
Object Storage Vendors – Compared
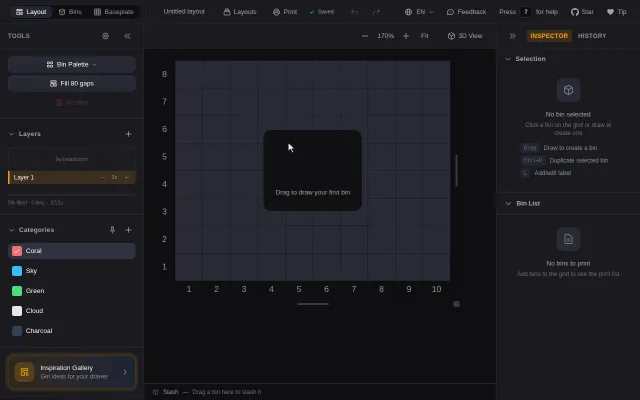
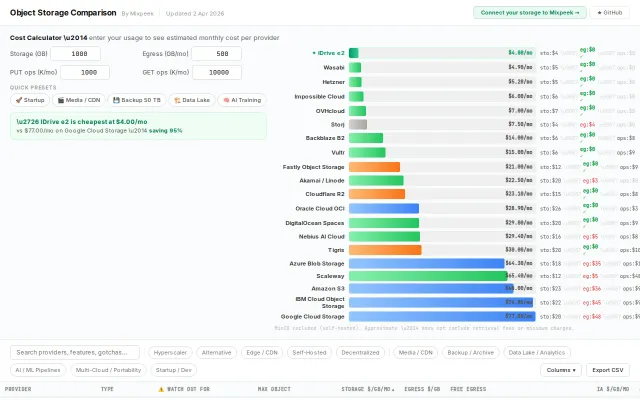
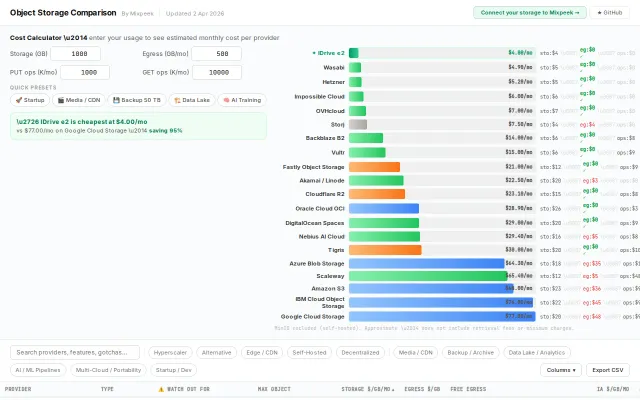
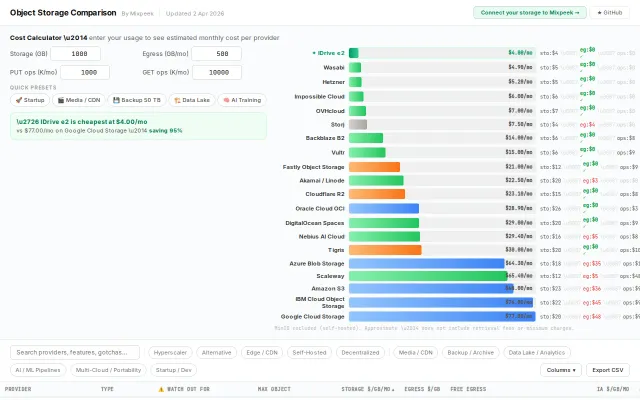
Object storage pricing with egress and ops costs—more specific than Vantage's general cloud calculator.
Solve My ProblemNiche Gem
Beefin
101mo ago
SandStore is a modular framework for building and experimenting with distributed storage architectures. Define your components once, swap implementations freely, and explore how fundamental design decisions, like where metadata lives or how your data plane behaves change the behavior of your system. Built for learners, researchers, and engineers.
Topology-as-variable via contract layer beats forking three codebases.
Distributed systems learners, researchers, engineers studying storage architectures
Ceph · MinIO · SeaweedFS
Sandstore is a hyperconverged distributed file system in Go. Every node runs control plane, data plane, and Raft consensus together. BoltDB metadata, full POSIX semantics, 2PC chunk lifecycle, gRPC, Kubernetes. The problem I kept hitting was simpler than any of that: I wanted to compare this design against a disaggregated one under identical workloads, and there was no clean way to do it without forking three separate codebases.
So topology became a variable. `topology/contract/` is a public Go package with two interfaces: `ControlPlaneOrchestrator` and `DataPlaneOrchestrator`. Implement them and you have a new storage topology. No fork. Same client, same benchmark suite, same Kubernetes deployment. The contract layer was stable before the first topology existed. It wasn't retrofitted.
I benchmarked against a 3-node localhost cluster (all nodes on one machine, real Raft replication but no network latency). Flush-forced 8MB writes: p50 1.1s, p99 1.4s. Reads: p50 1.8ms, p99 363ms. Topology 2 is a GFS-style disaggregated design. The comparison I actually want to run is hyperconverged vs disaggregated under identical workloads on the same hardware. That result doesn't exist anywhere in a single codebase right now.
This isn't production storage today. The longer goal is that you have an idea for a storage topology, you implement the interfaces, and Sandstore handles the benchmarking, deployment, and comparison. No surrounding infrastructure to build from scratch. Website: https://sandstore-eta.vercel.app
If you've run both hyperconverged and disaggregated seriously, where did the tradeoffs actually show up?
Object storage pricing with egress and ops costs—more specific than Vantage's general cloud calculator.
Parametric CAD library baked into a drag-and-drop layout tool for 3D printing.
Compares 30+ storage providers with real cost calculator including egress and ops.
VR-guided code generation sounds bold, but lacks working demo or verifiable technical proof.
Cloud cost calculators exist everywhere — this one just covers more providers.
Technical deep-dive on NVMe optimization, but this is a blog post, not a product.