Developer Tools●●Solid

Alodb – I got tired of pasting my Postgres schema into ChatGPT
Local NL-to-SQL when DataGrip and TablePlus already offer AI features.
Solve My ProblemNiche Gem
eyvzov
411mo ago
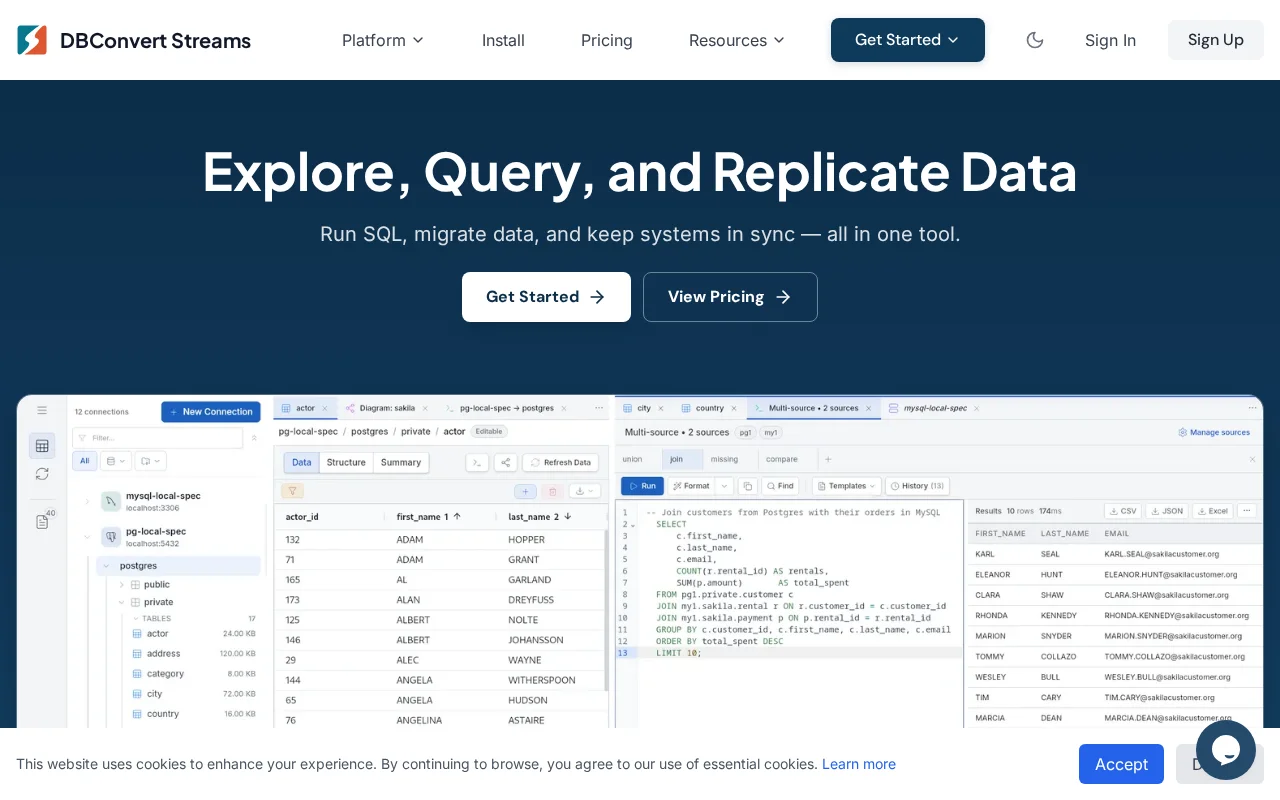
Join Parquet files with live PostgreSQL tables directly — no export or extra tooling needed.
Data engineers, backend developers
Airbyte · Debezium · DBeaver
- explore schema in one tool - write and test queries in another - run the migration separately - set up CDC sync somewhere else
Each tool does its job fine. But the switching, glue scripts, and "wait, which connection config was this?" start to add up.
So I built DBConvert Streams 2.0, a self-hosted tool that keeps the whole workflow in one place:
explore -> verify -> migrate -> keep in sync
What it does:
- connect to PostgreSQL, MySQL, CSV/JSON/Parquet, S3-compatible storage - browse schemas and data - run SQL queries (including across different sources) - run one-time migrations or continuous CDC sync
The cross-source SQL part was the main thing I personally kept missing - usually this required exporting data or setting up extra tooling.
Tools like Debezium and Airbyte solve the pipeline side well, but I still ended up switching to other tools to explore and query data before or during the move.
Runs as a desktop app (Windows, macOS, Linux) or via Docker.
Local NL-to-SQL when DataGrip and TablePlus already offer AI features.
Yet another Go config merger competing with Viper and Koanf in a saturated market.
Spec-first approach competing against LinkedIn and W3C Verifiable Credentials with no working implementation.
Multi-platform promo posts from one draft, but Buffer, Later already own this niche.
Email-to-JSON with schema validation and webhook delivery, but LLM extraction isn't novel.
Yet another disk usage TUI when ncdu and gdu already dominate this space.