Data●Mid
I used NLP to turn UK planning PDFs into a clean CSV
Useful dataset for UK researchers but it's a Kaggle upload, not a reusable tool.
Niche Gem
david_s_data
132mo ago
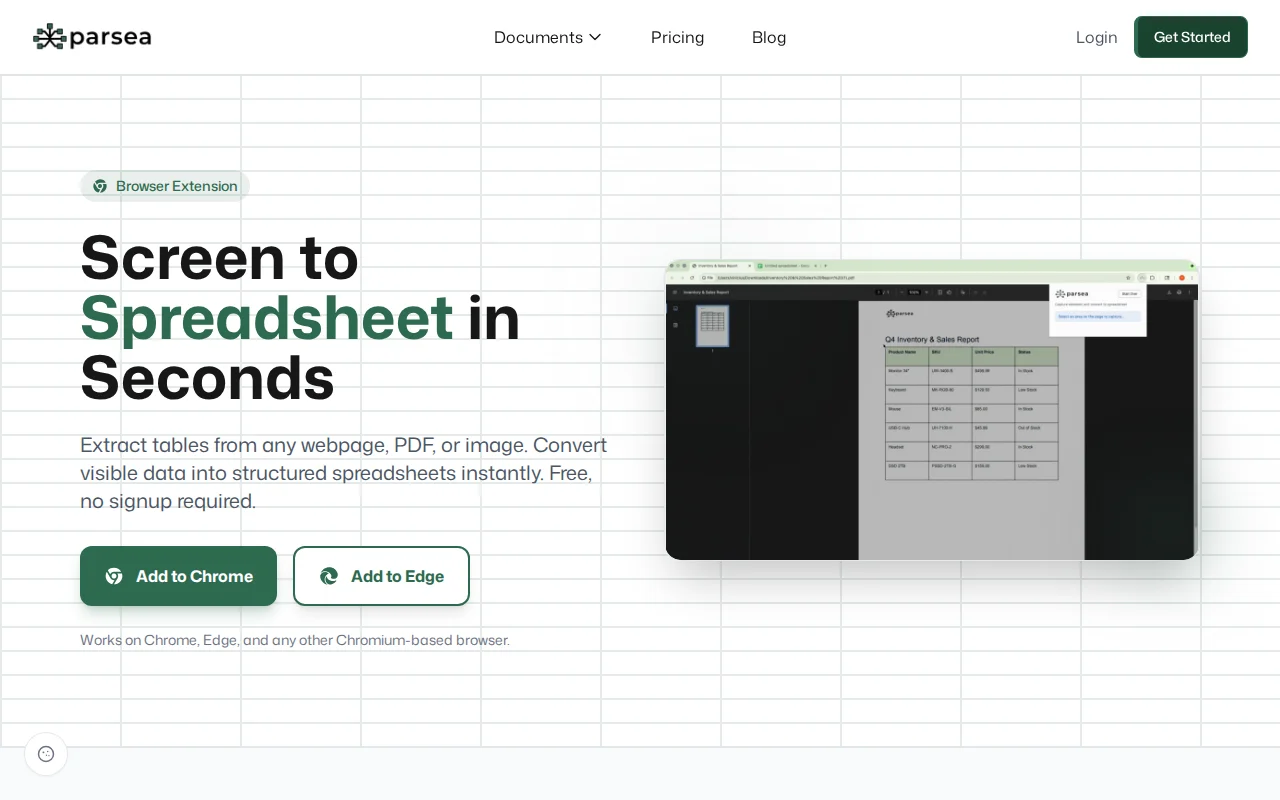
OCR-based extraction handles images and PDFs where standard DOM scrapers fail.
Data analysts, researchers, office workers
TableCapture · Jina AI Reader · Nanonets
My tool uses OCR instead of looking at the page code. It sees what you see on the screen and turns it into a spreadsheet. Since it does not rely on the underlying code, it works on almost anything in your browser.
It's free. Would love to get your feedback.
Useful dataset for UK researchers but it's a Kaggle upload, not a reusable tool.
CPU-only OCR with clipboard in/out beats Tesseract for modern screenshots.
94.5% accuracy, self-hostable, open source—beats Textract on cost and accuracy.
CPU-only VLM OCR beats Tesseract accuracy without sending data to the cloud.
Useful for quick cleanup, but JinaAI and LLMs already handle this natively.
Offline Ollama + OCR keeps your documents private when cloud APIs won't.