Developer Tools●●Solid
Save, an API that turns any URL into clean Markdown for LLMs
HTML-to-Markdown for LLMs when JinaAI and Firecrawl already exist.
Solve My ProblemSlick
jswallez
301mo ago
Beats Firecrawl on token count for Cloudflare sites when you need local execution.
Developers building RAG pipelines or LLM agents needing web context
Firecrawl · Jina AI Reader · Crawl4AI
Needed any URL as clean Markdown for LLM context — including Cloudflare/anti-bot sites. curl gets HTTP 403 on those, raw HTML is 80%+ nav noise eating context, paid SaaS (Firecrawl, Jina) wasn't an option for me.
It's a Docker wrapper around two existing OSS tools — CloakBrowser (stealth Chromium that passes Cloudflare) and rs-trafilatura (HTML → Markdown). No new scraper, just glue. Runs locally, my URLs stay on my box
Token reduction (raw curl HTML vs snitchmd, tiktoken cl100k_base):
- cloudflare.com/learning/bots — curl: HTTP 403 → snitchmd: 0.8k
- docs.docker.com/engine/install — 187k → 0.9k
- en.wikipedia.org/wiki/LLM — 222.7k → 29.7k
Heads up: passes Cloudflare, can't solve "click traffic lights" captchas (reCAPTCHA v2, hCaptcha)
MIT. Happy to answer questions
HTML-to-Markdown for LLMs when JinaAI and Firecrawl already exist.
Replaces localhost tunnels for sharing Claude artifacts with stable Cloudflare URLs.
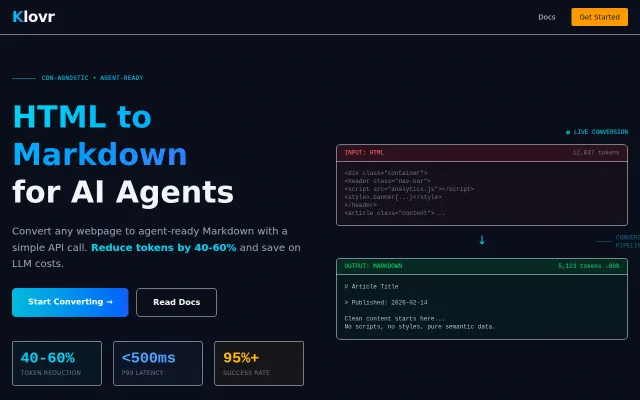
Nice, focused product: site-specific extraction rules (CSS selectors/metadata overrides), edge-first delivery (<500ms p99) and SDKs for Node/Python make it quick to drop into an LLM pipeline and claim 40–60% token savings. That said, HTML→Markdown is a crowded niche (Pandoc, Jina, Firecrawl and dozens of scrapers already exist), so Klovr needs clearer differentiation — e.g. demonstrable extraction accuracy, enterprise-grade rule sharing, or unique model-aware trimming — to move beyond 'handy utility'.
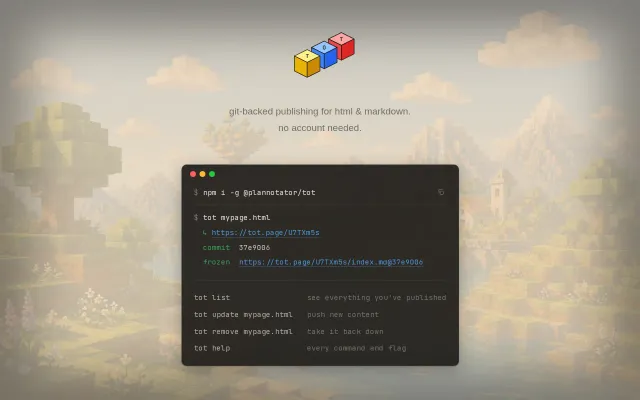
Git-backed static hosting with no signup, but GitHub Gist already does this free.
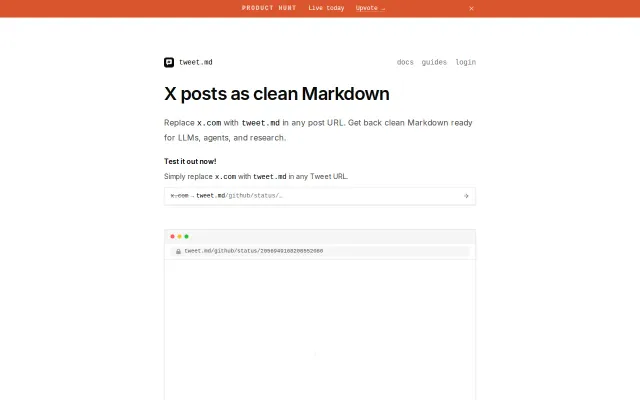
Turns messy X threads into clean Markdown for LLMs better than generic scrapers.
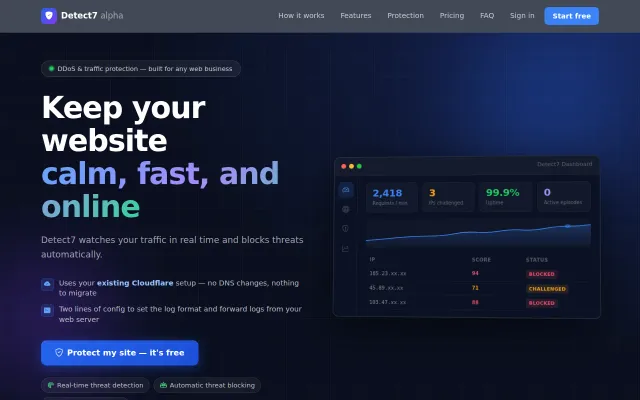
Cloudflare already does DDoS protection; this adds AI scoring on top.