Security●●Solid
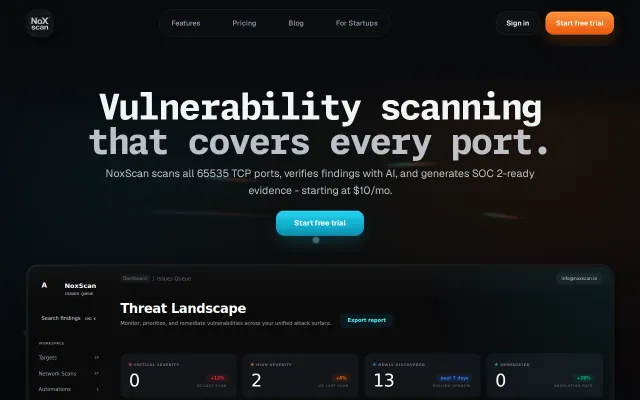
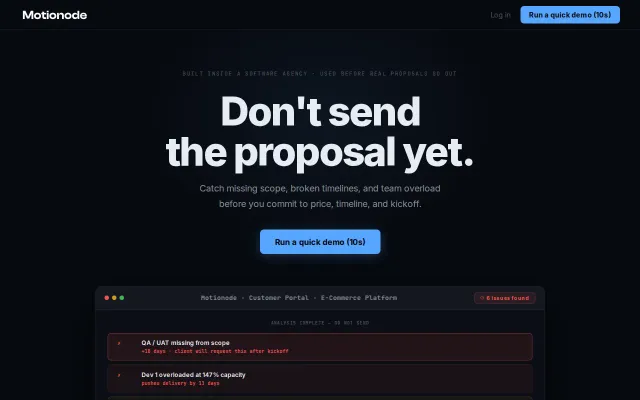
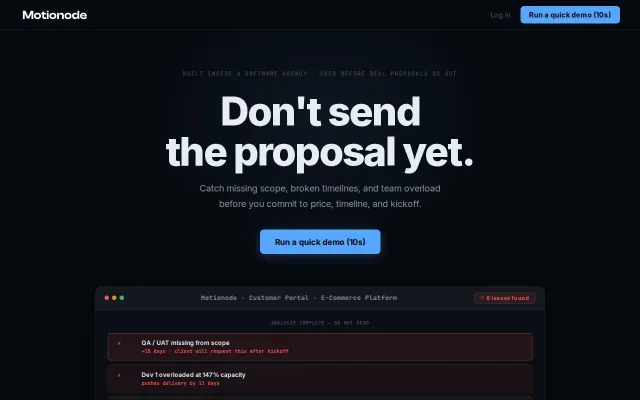
Noxscan.io 65K Port and Vuln scanner with LLM false-positive filtering
Full 65K port coverage at $10/mo undercuts enterprise scanners charging 70x more.
Solve My ProblemSlick
caudena
103mo ago
Open-source AI vulnerability discovery
Found real bugs in n8n and Vercel AI SDK using a three-agent verification pipeline.
Open source maintainers and security engineers
Snyk · CodeQL · Semgrep
n8n: password-reset JWTs being logged at debug level (n8n-io/n8n#29405) Vercel AI SDK: role: "system" injection in createAgentUIStream, a runtime schema bypass in ToolLoopAgent, and a prototype-property collision in getMediaTypeFromUrl (vercel/ai#14749, #14750 merged, #14751 merged) LangGraph.js: NoSQL injection in MongoDBSaver via unvalidated thread_id / checkpoint_ns / checkpoint_id types (langchain-ai/langgraphjs#2353) browser-use: path traversal in remote-fetched templates.json fields (browser-use/browser-use#4777) Haystack: SSRF and arbitrary file read via unrestricted OpenAPI $ref resolution, path traversal in the image converter, and unbounded HTTP body reads in LinkContentFetcher (deepset-ai/haystack#11226, #11228, #11229)
The false positive rate got low enough that I'd rather have other people running it than keep it private, so it's now public under Apache 2.0. How it works:
Analyst (1 LLM call): reads the repo and picks 50 to 500 files to deep-scan based on entry points, third-party surface, and dangerous sinks. Researcher (per file): walks call chains and writes raw findings. QA (per file): re-reads the code against each claim with no access to the researcher's reasoning, and rejects anything that doesn't have a real attack vector. Keeping the QA agent isolated from the researcher is what got noise under control. If it sees the researcher's reasoning, it just agrees with it.
Each agent runs in its own query() session through the Claude Agent SDK with a filesystem sandbox scoped to the target repo. Cost is tuned for open models. About $0.50 per file with Qwen 3.6 plus DeepSeek v4 Pro on OpenRouter. OpenAI is around 2.5x that. Anthropic is around 10x. npm install -g probus probus scan ./my-app Things I'd like feedback on:
The QA prompt took the most iteration. Happy to walk through it if anyone is working on similar verifier-agent patterns. I want to publish a public benchmark against a vulhub-style corpus. Suggestions on which repos to run it against would be helpful. The analyst step is a single LLM call right now. On large monorepos it sometimes misses things. Thinking about a hierarchical version.
Full 65K port coverage at $10/mo undercuts enterprise scanners charging 70x more.
Slack-to-PR decision tracking, but landing page shows a different product entirely.
Slack-to-PR decision tracking, but landing page shows a different product entirely.
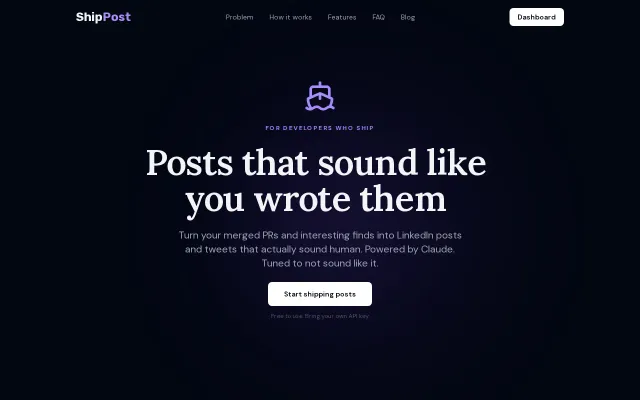
AI-generated LinkedIn posts from PRs — solving a problem most devs don't have.
Full issue-to-merge automation for Claude Code when most agents stop at code generation.
GitHub Action quizzes devs on their PR diff using Claude before merging.