Gaming●●Solid
Hanaco Garden – A Calm iOS Garden
Cozy creature-collection garden with cloud backup, no pressure gameplay.
CozyEye CandyCrowd Pleaser
tsuyoshi_k
414mo ago
Serverless search for the old weird web when Google only finds SEO slop.
Developers, digital archivists, indie web enthusiasts
Kagi · Marginalia Search · Stract
So I built Gulugulu to fix this for myself. It's a search engine that only indexes the old/weird web like digital gardens, Neocities pages, ASCII art, and personal projects.
There is no backend. It's a static site hosted on GitHub Pages.
You can try it here: https://cbrincoveanu.github.io/gulugulu/
The search runs entirely in your browser using Fuse.js against a single, flat index.json file. To get the data, I wrote a Python crawler that specifically scrapes curated indie webrings (like 512kb.club and Cloudhiker), extracts the basic metadata, and dumps it into the JSON array. Because it's completely serverless, there are zero analytics, no ads, and no cookie banners.
Obviously, loading a massive JSON file into browser memory has a hard upper limit. Right now, the index is small enough that client-side search feels instant. To scale it without melting mobile browsers, I'm working on a deeper crawler (depth=2) that runs URLs through an LLM to score their quality. If a site looks like commercial spam, it gets dropped before appending to the json.
I'd love feedback on the client-side Fuse.js performance. Also, the index is still pretty small. If you have a personal blog, a digital garden, or know any weird RSS feeds, please drop them in the comments and I'll add them to the crawler's seed list!
Cozy creature-collection garden with cloud backup, no pressure gameplay.
FUSE filesystem trick makes grep usable on notebooks without modifying source files.
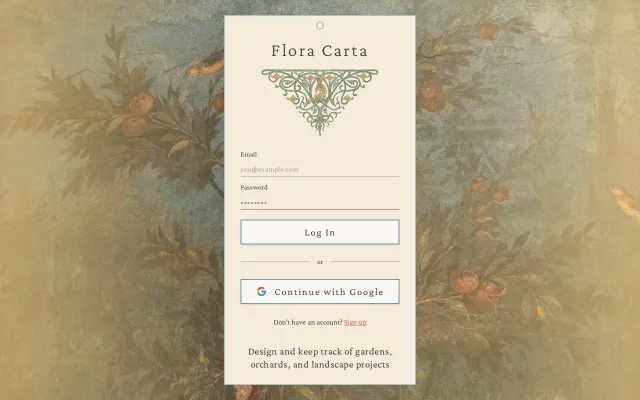
The site nails a vintage botanical aesthetic and exposes basic account flows (email + Google sign-in) — it feels like the author's personal plant inventory opened to the public. It's clearly early: the landing promises tracking of varieties and planting years but shows no sign of bulk import, geotagged plant pins, photo timelines, or care/reminder features that would make it genuinely useful at scale. Add CSV import, location mapping, and recurring care reminders and this could move from a charming prototype to an indispensable tool for serious hobbyists.
Pixel-perfect sand-raking simulator, but it's a novelty—no persistence, no real game loop.
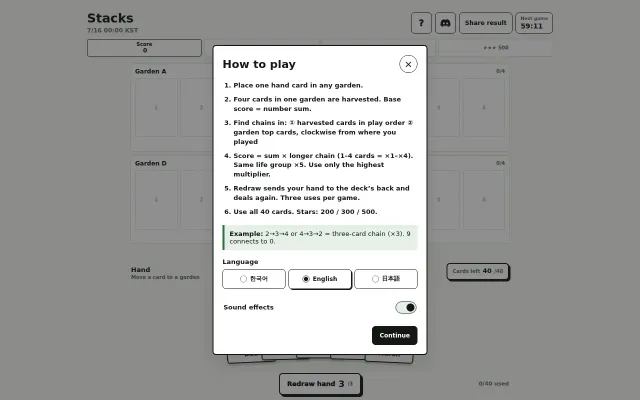
Hourly cadence and chain multipliers make this solitaire variant genuinely fresh.
Mergerfs alternative skipping FUSE entirely for easier scripting and installs.