Gaming●Mid
Cockroach Battle Royale Game
Cockroach battle royale with corpse-eating mechanics, but it's just a single-player arcade loop.
CozyShip It
AFF87
121mo ago
Impressive vertical slice, but GenAI asset pipelines are becoming table stakes for solo devs.
Warhammer 40K fans, indie game developers, AI tooling enthusiasts
Battle Brother · Gladius: Warhammer 40,000
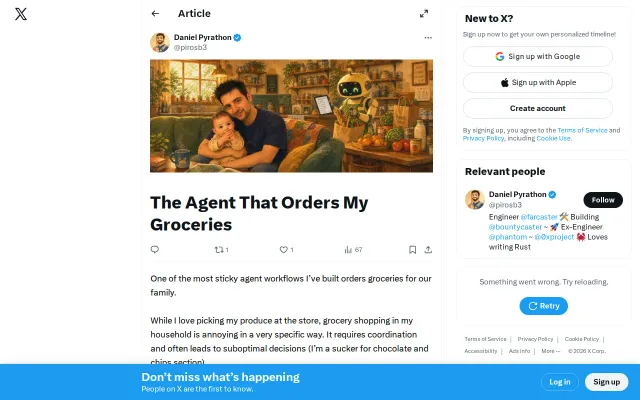
For sprite generation, whilst creative exploration was fast, getting high-quality and consistent images was hard. Gemini ended up stylistically best here but I had to use BiRefNet for background removal. While I experimented with Claude for map generation and layout I ended up finding it fastest to build a full Editor and layout maps myself.
Suno, IMO, has gotten really good at background music. ElevenLabs SFX and voice APIs were decent but only after A LOT of tweaking. SFX prompts needed to be grounded in familiar terms (i.e. no sci-fi references in prompts) and be > 2s long. For voice, I ran ElevenLabs v3 and v2 head-to-head with the same Voice Design voices routed through both; v2 sounded materially better for character work than v3.
For coding, I settled on Claude Code + Opus 4.7 with SSH/tmux/mosh. For long running subagents I found OpenClaw especially unreliable so gave up on it early. I also found that despite Opus 4.7 being an incredible model for coding it still requires constant supervision to avoid architectural drift. This was especially true when UX/UI systems needed to be built. For code bases as large as this (~120k LoC) I've yet to pull off full "Human On The Loop" even with comprehensive custom skills + SOTA Context Engineering (i.e. > 30 mins not needing to check in).
Maybe I'm doing something wrong here though?
The AI player is a hand-tuned utility scorer, weighted considerations over candidate actions. This is where I found LLM authoring uniquely strong: Claude read competitive 40K tournament reports, extracted positioning principles, and encoded them as considerations. The weights themselves were then tuned through AI-vs-AI self-play, so the loop you'd want from a learned system is there, just at the weight level rather than the policy level. Full self-play over a learned policy isn't feasible yet with the ruleset still being authored and not enough stable surface area or game data.
Feedback welcome both from 40K players on overall interest in the concept, and from anyone who's pushed further on Human-on-the-Loop with a codebase this size.
Cockroach battle royale with corpse-eating mechanics, but it's just a single-player arcade loop.
Cockroach battle royale with corpse-eating mechanics but no multiplayer yet.
Reveals indie launch trends like Vercel hosting 33% of new products.
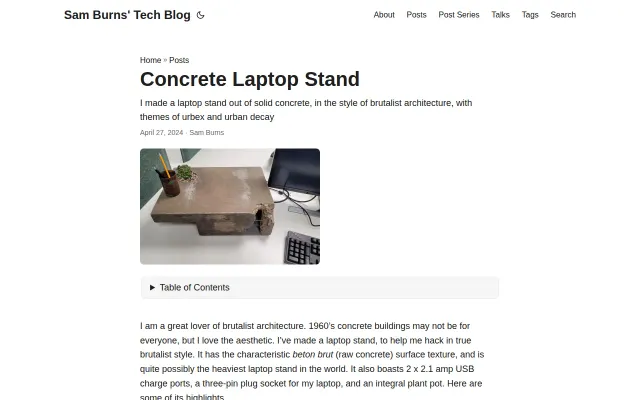
Heavy concrete stand with built-in USB ports and a plant pot for your desk.
Ghostty-native vertical tabs + AI notifications where split panes fail.
Unrestricted local strategy execution via WASM simulator—no compute or library limits.