Developer Tools●●Solid
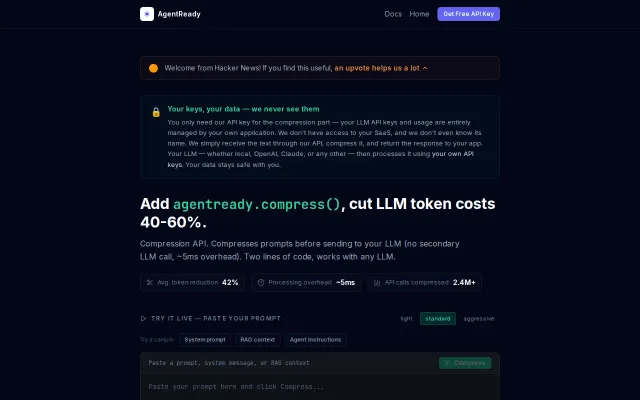
I cut LLM API bill by 55% with a Python text compressor, no AI involved
Prompt compression cuts token costs 40-60%, but it's lossless text optimization, not a novel insight.
Solve My ProblemShip It
christalingx
313mo ago
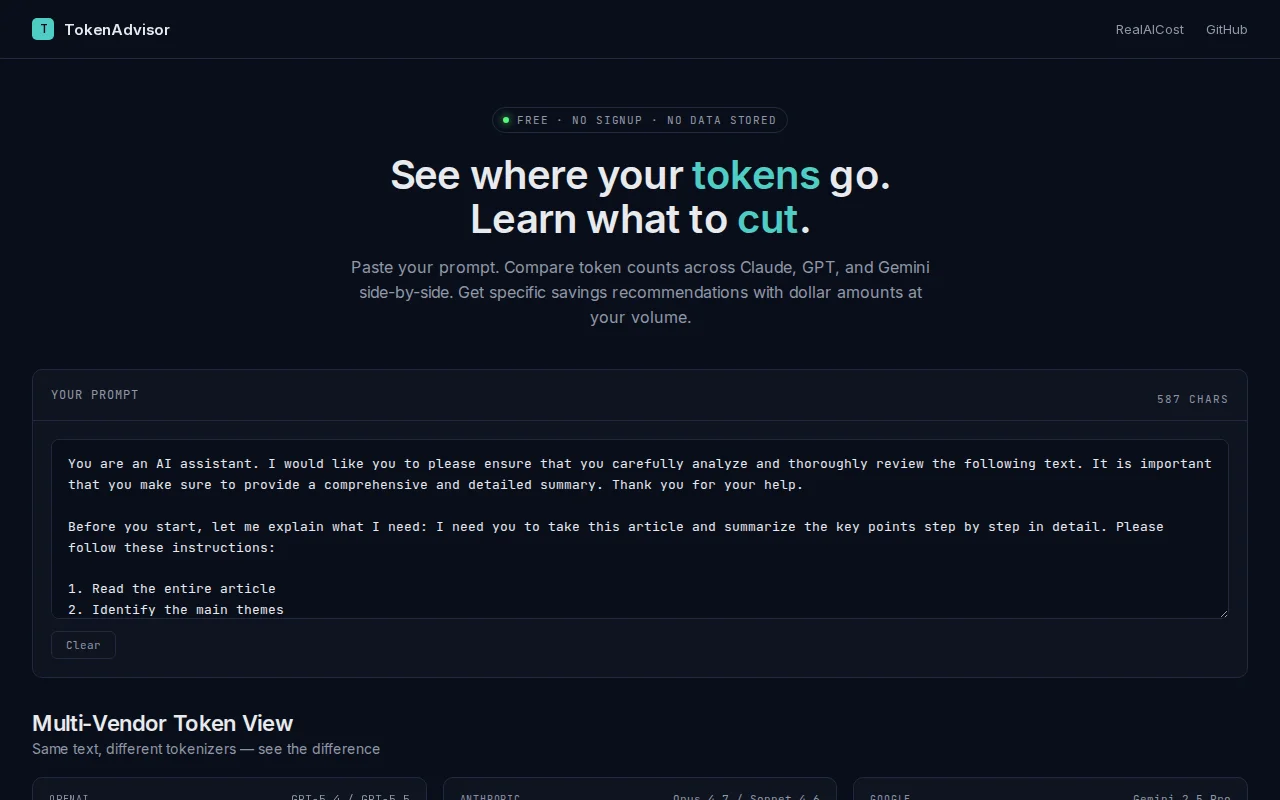
Multi-vendor token comparison with specific cut recommendations and dollar savings at scale.
Developers building with LLM APIs, teams managing AI costs
PromptPerfect · tiktoken · LLM cost calculators
Prompt compression cuts token costs 40-60%, but it's lossless text optimization, not a novel insight.
If you're burning through Claude/OpenAI credits, this is a low-friction stopgap: it classifies prompts in ~10ms and routes trivial tasks to cheaper/local models while reserving premium APIs for complex work. The agentic-task detection, reasoning-aware routing, session pinning and context-window fallback are practical touches that avoid mid-thread model bouncing and 429 failures. It isn't reinventing the space (OpenRouter and others exist), but it's focused on real-world cost tradeoffs and drop-in compatibility.
Another AI security wrapper in a crowded market, but agent-side integration is interesting.
Makes billing config prompt-operable; non-engineers can change pricing via their IDE.
Three-line wrapper cuts LLM costs 80%+ via prompt classification and same-provider routing.
Drops token usage 97% and blocks injection — smart sanitization beats raw WebFetch, drop-in replacement.