Security●●Solid
OpenHack – OSS security scanner, 40x cheaper, on par with Opus 4.6
Actually spins up Docker to exploit findings instead of just flagging them.
WizardryBig Brain
ananayarora
1204d ago
Post-trained model for offensive security instead of wrapping GPT with safety refusals.
Security engineers, DevSecOps teams, backend developers
Snyk · Semgrep · Datadog Security
The reason this exists: most "AI security" tools wrap a general model, so they inherit its refusals — point one at a real offensive task and it hedges or declines, because the base model was trained to. We went the other way and post-trained our own model for offensive security, so it does the work instead of apologising for it. It's our model, not a wrapper.
Under the hood it's a multi-agent swarm: an orchestrator splits the job across subagents running in parallel, each owning a slice, then synthesises one report. That's what gets a polyglot microservice repo done in one pass.
The fair objection to a model that doesn't refuse, pointed at your code: how is that not reckless? I think refusals are the wrong layer to put safety in. A model that refuses is both useless (won't do the job) and unsafe (you're trusting a probability distribution to hold a hard line). So we don't ask the model to behave — we enforce it in the harness. A runtime guard written in Go intercepts every tool call before it runs. In scan mode it hard-blocks every mutating tool and any non-read-only shell command — the model can decide whatever it wants, the guard won't let it write. In pen-test mode the same guard pins the agent's network scope to the targets you authorised; it can't reach anything else. Safety is deterministic and sits below the model, not inside it.
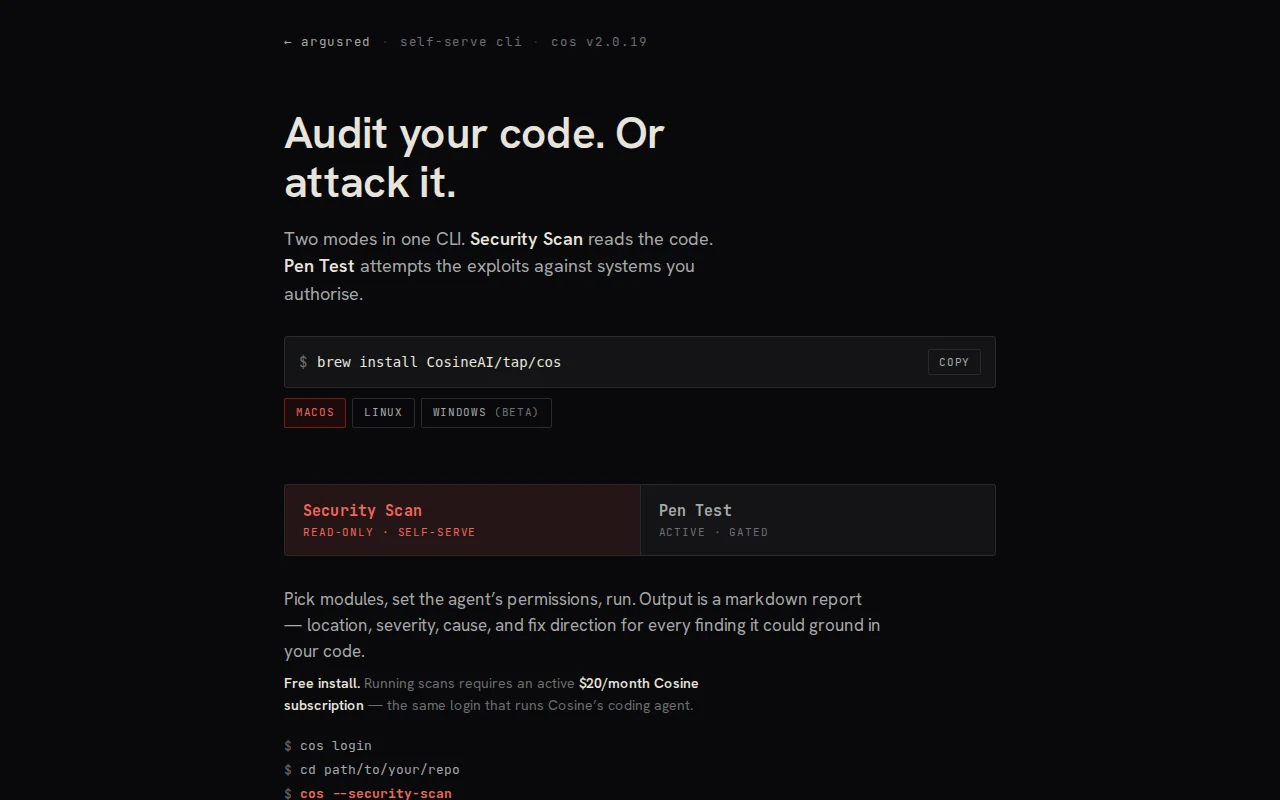
Two modes, one CLI:
- Security Scan - read-only audit of a local codebase, every finding tied to a file and line. Free, runnable today.
- Pen Test - the swarm attacks systems you authorise and hands back the request it sent and the response your code gave. Gated behind written authorisation.
Demo target, and I'll be straight about it: Bank of Anthos, Google's open-source reference bank. Known app, some intentionally-soft bits — which is why I picked it, so you can reproduce the run instead of trusting a screenshot. The scan found an integer overflow in the transfer path that would let you forge an account balance, plus the usual injection/auth/secrets classes.
It's a closed binary (brew/curl/winget), runs locally, by Cosine. Run it behind a firewall and `tcpdump` exactly what it does before you trust it on anything real. Install is free; the scan runs on a $20 Cosine subscription; pen test is scoped per engagement.
I'll be in the thread all day. The harness-vs-refusals design is the part I most want torn apart - tell me where it breaks.
Actually spins up Docker to exploit findings instead of just flagging them.
First automated red teaming for agentic AI at scale—enterprise gap now weaponized.
Single-file, zero-dep scanner for a niche product, but OpenClaw audience is tiny.
MCP-specific guardrails when Claude ecosystem lacks native security scanning.
Bundles CI-friendly scanners that target agent-specific risks: 17 patterned secret detectors, prompt-injection and instruction‑malware heuristics, tool/SSRF and MCP auth checks, plus SARIF/JSON outputs for integration. Findings map to the OWASP Top 10 for Agentic Applications (2026) and it adds 'harden' profiles to apply safer defaults to OpenClaw/MCP installs — practical, focused ops tooling rather than a generic secret-finder.
Catches malicious skills before they steal your AWS keys or pipe data exfiltration.