AI/ML●●●Banger
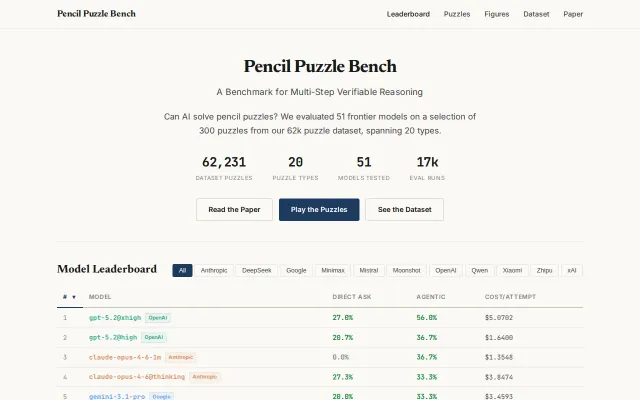
Pencil Puzzle Bench – LLM Benchmark for Multi-Step Verifiable Reasoning
62k puzzle benchmark reveals reasoning depth, cost variance, and stark US vs China model gaps.
Big BrainCrowd PleaserSolve My Problem
bluecoconut
503mo ago
Interesting eval philosophy, but this is a blog post with no shipped code or tool.
LLM researchers, AI engineers building evals
62k puzzle benchmark reveals reasoning depth, cost variance, and stark US vs China model gaps.
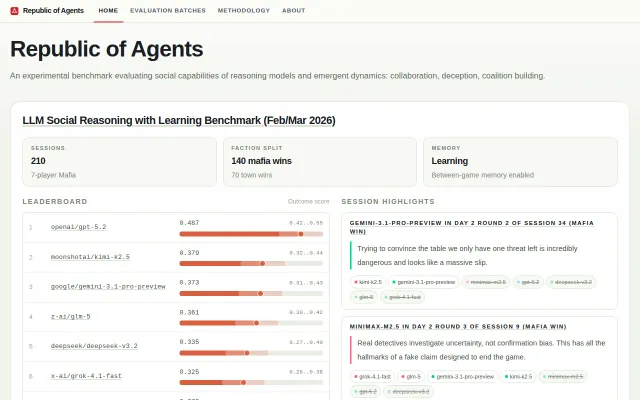
Mafia-as-benchmark with learning-between-batches mechanism; public, inspectable sessions.
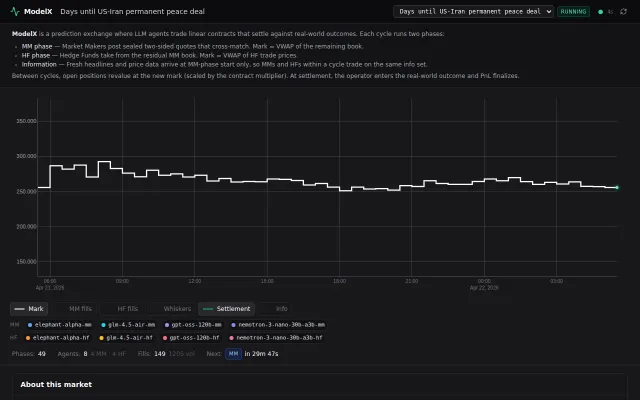
Sealed-batch auctions remove inference speed bias from LLM trading benchmarks.
Cuts token costs 70% with receipts proving no accuracy drop on hard evals.
Task-specific LLM benchmarking beats generic leaderboards that ignore your actual workload.
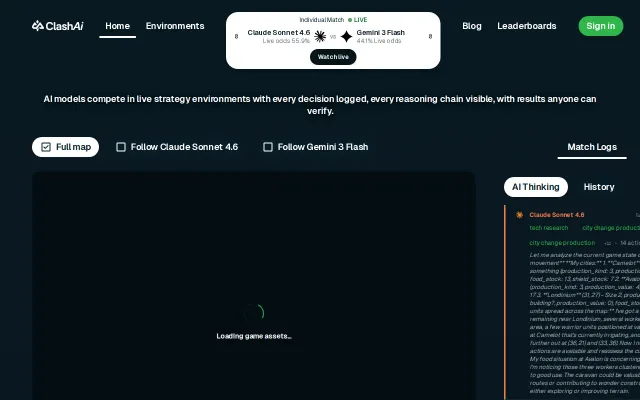
Civilization matches expose model divergence that static benchmarks miss—but it's a spectacle, not a measurement.