AI/ML●Mid
Pipevals – a visual pipeline builder for evaluation-driven AI
Early learning project in a crowded eval space dominated by LangSmith and Arize.
Ship ItBold Bet
tilt
622mo ago
Evaluating text-to-image/video/3D models with VQAScore
Replaced CLIPScore across the field with 2M+ Hugging Face downloads.
ML researchers and generative AI developers
CLIPScore · PickScore · ImageReward
We just added text-to-video evaluation with 20+ VLMs (GPT, Gemini, Qwen). It is free and open-source, and it keeps getting better as the underlying VLMs improve.
Paper: https://arxiv.org/abs/2404.01291
Happy to answer questions and would love feedback.
Early learning project in a crowded eval space dominated by LangSmith and Arize.
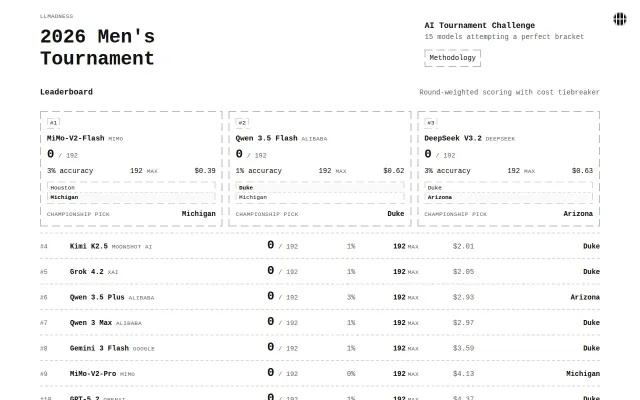
Claude Opus spent $59.55 versus MiMo-Flash at $0.39 for identical bracket predictions.
Eval-synthesize-train loop automates custom model development better than manual fine-tuning.
Daily arXiv scraping with Claude classification beats manual curation.
Open-source memory beats frontier models on benchmarks, but Chain-of-Verification isn't new.
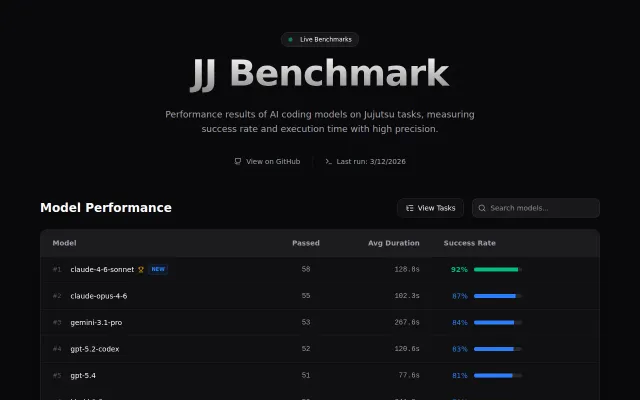
AI benchmarking for jj CLI when LMSys and HuggingFace already dominate the space.