AI/ML●Mid
FalsoAI – Detect influence/manipulation patterns in content
Cybersecurity for your brain sounds compelling, but the MVP lacks technical depth.
Bold Bet
liam-chen
1001mo ago
Real-time pattern detection
Embedding-based news coordination detector with AVX2 cosine similarity. Novel domain, but unproven for trading signals.
Quant researchers, financial analysts, market microstructure researchers exploring narrative coordination
Refinitiv sentiment analysis · Bloomberg narrative tracking · Academic financial linguistics research
Cybersecurity for your brain sounds compelling, but the MVP lacks technical depth.
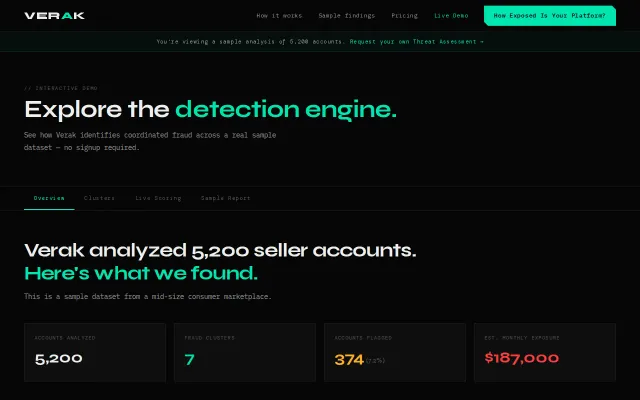
Clusters coordinated fraud rings via timing, infrastructure, referral patterns—real forensic thinking.
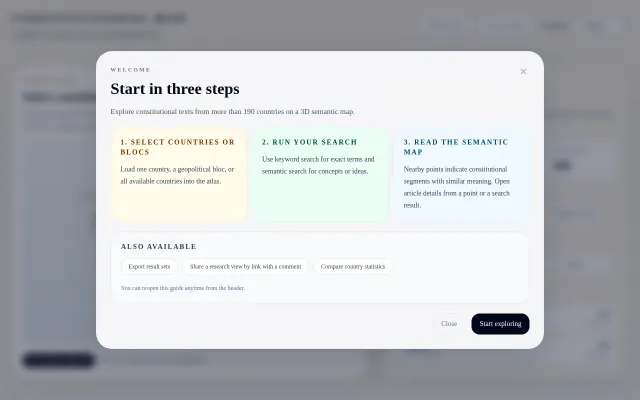
3D UMAP visualization finds conceptually similar constitutional provisions across 188 countries.
Local LLM email parsing when Plaid and receipt scanners already exist.
Psycho-security is a compelling angle, but this MVP lacks technical differentiation.
Embedding auditor with 5 checks and pretty plots, but crowded niche with unclear novelty.