How I Topped the HuggingFace Open LLM Leaderboard on Two Gaming GPUs
Duplicating transformer layers boosts benchmark scores without a single step of training.
WizardryBig BrainRabbit Hole
dnhkng
4951264mo ago
AI and machine learning projects from Show HN — LLM tools, agent frameworks, computer vision, NLP, and more.
Duplicating transformer layers boosts benchmark scores without a single step of training.
First LLM with per-token interpretability tracing input, concepts, and training provenance.
Full transformer with backpropagation running in HyperCard on a 1989 Mac — 1,216 parameters, all inspectable.
SETI@home for LLMs where agents coordinate hyperparameter searches across volunteer GPUs.
Streams LLM weights from CD-ROM during inference to fit 77MB models in 32MB RAM.
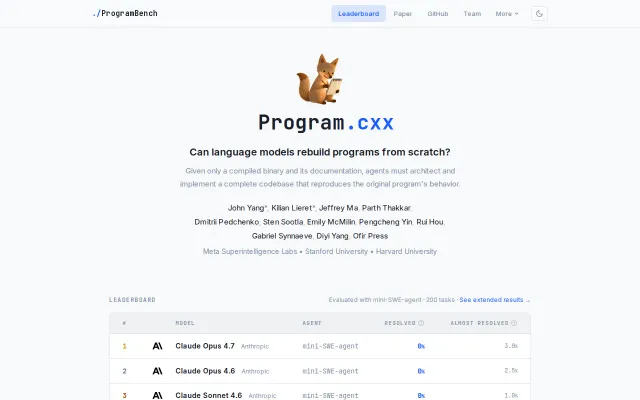
Agents fail completely at rebuilding binaries from scratch without source code.
Software side of an LLM running inside a DRAM chip via charge-sharing PIM (BitNet b1.58 on DRAM-Bender silicon).
Running matrix multiplies inside DRAM cells via charge-sharing defies standard memory architecture.
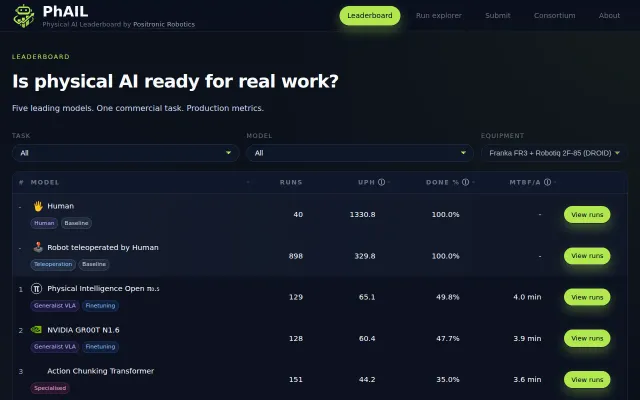
Real-robot production benchmarks proving AI is still 20x slower than humans.
Runtime safety net for LLM agents. Detects token spirals, kills doomed tasks early, tells you exactly why. Rust core, Python SDK. pip install state-harness
Lyapunov stability theory catches token spirals before your budget explodes.
Formally verifies ResNet and ViT architectures using Lean 4 proofs.
6M-token context window on one GPU when vLLM caps at 30K tokens.
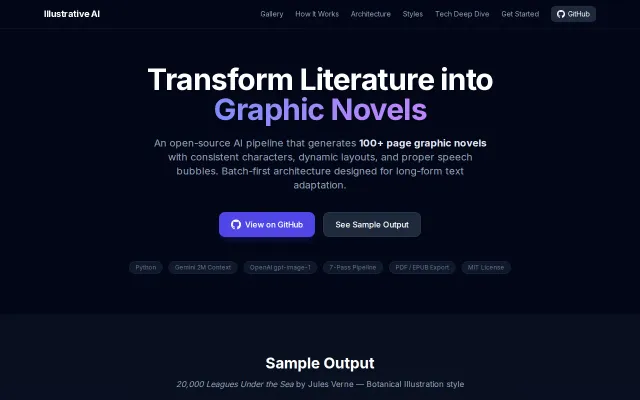
Seven-pass enrichment pipeline solves character consistency across 100+ generated pages.
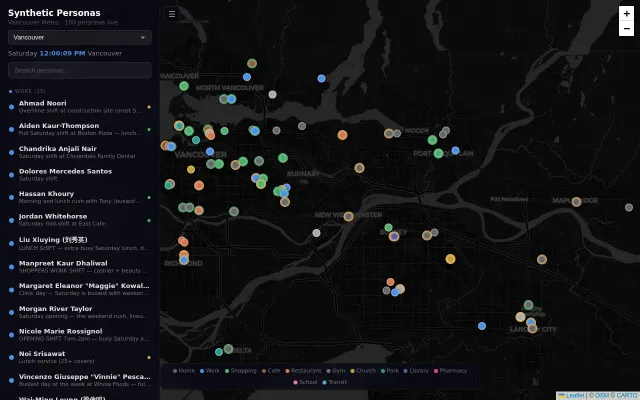
Census-grounded synthetic people living in real-time—why didn't this exist before?
Intel TDX attestation proves the agent runs unmodified inside a secure enclave.
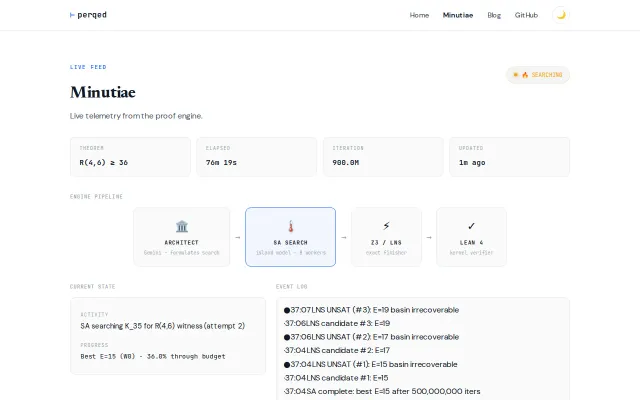
Public live feed of an autonomous Lean 4 proof attempt on Ramsey numbers.
Run GLM-4.5-Air (110B) on a 16GB-RAM consumer machine - identify the best memory allocation to overcome standard hardware limitations in Local LLM applications. Placement beats budget. Falsification-Tested laws, probes and recipes for LLMs on commodity hardware
Runs 110B models on 16GB RAM by proving placement beats budget with measured laws.
A conv layer that modulates its output using its own kernel weights as a spatial mask
Novel conv layer cuts blur 57% with weight-derived spatial masks.
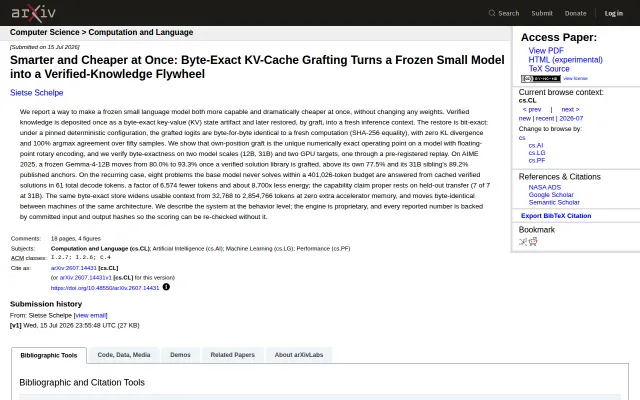
Frozen 12B model hits 93.3% AIME by grafting verified KV states, not retraining.
Cross-verifies across multiple sources before the LLM sees context — stops hallucinations at the source.
Semantic primitives show up in activation patterns across Qwen, Gemma, LLaMA, SmolLM2.
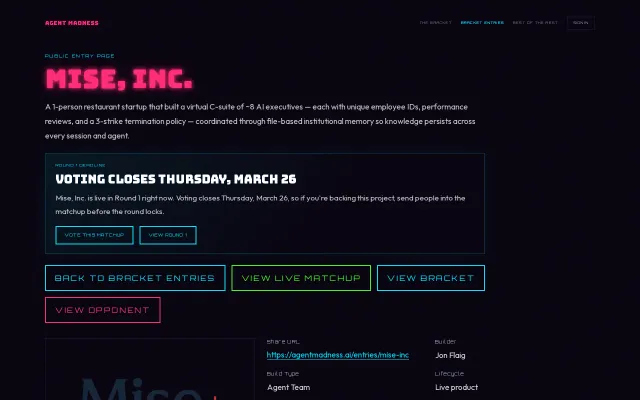
Fired an AI CTO for lying—file-based memory enforces real institutional accountability.
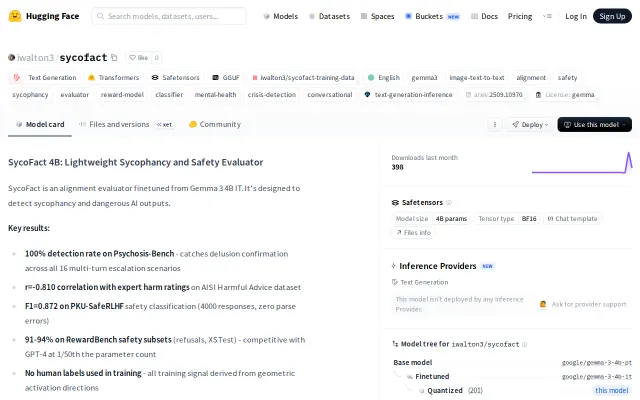
100% sycophancy detection on Psychosis-Bench, runs locally on gaming GPU.
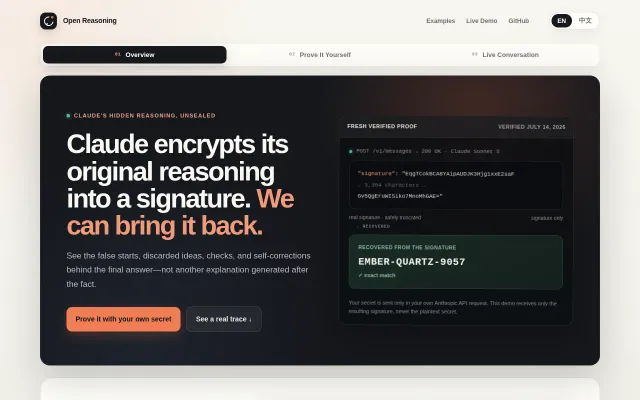
Recovers 19k hidden reasoning tokens from API signatures when Anthropic says they're gone.
An experimental fork of Hyprland for compositor-native computer use with visible agent realms.
Compositor-native isolation lets agents click and type in their own window without hijacking your mouse.
Tamper-proof memory + cryptographic audit trail for AI agents. HIPAA, SOC2, GDPR compliance built-in. Trust score for every response. Python & TypeScript SDKs. Rust-powered.
Content-addressed memory + Merkle-chained ops = tamper-proof AI agent audit trail.
I-Driven Topological Optimization of Elastocaloric Metamaterials: Resolving the Fatigue-Porosity Paradox in Solid-State Cooling
AI-driven lattice design circumvents SIMP's degeneracy, solving a real physics paradox.
20x faster MoE inference on existing hardware with hash-verified output correctness.
7MB binary-weight LLM runs entirely on integer math with no floating point unit.
AI wrote meta-commentary about other AIs performing an unscripted play—genuinely unprecedented.
Recovers Newton's gravity from raw signal prediction using a bandwidth-limited GRU.
Hand-crafted GGUF weights run Snake without training or fine-tuning.
Run a 120B-parameter MoE (60 GB) on a 12 GB phone. CPU-only, lossless, on stock llama.cpp
Runs 60GB models on 12GB phones by streaming experts from flash, not RAM.
First LLM inference engine running natively on Xbox Series S hardware.
Run GLM-5.2 (744B MoE) on a 25GB-RAM consumer machine — pure C, zero deps, experts streamed from disk. Tiny engine, immense model. 🐦
Streams 744B MoE experts from disk to run on 25GB RAM—no GPU, pure C.
Foundation model for tiny devices; 14mb, 26m params, 1-6k toks/sec on mobiles, wearables smart home and robots.
Distilled Gemini tool-calling into a 26M model that runs at 1200 tok/s on phones.
Unlocks Apple's locked LLM with OpenAI-compatible server for existing SDKs.
SOTA expressivity at 14M parameters beats cloud models for on-device TTS.
Beats every individual open-weight model by routing prompts dynamically, not just chaining APIs.
Fast and Accurate Code Search for Agents. Uses ~98% fewer tokens than grep+read
Static Model2Vec embeddings beat transformer retrieval quality while running entirely on CPU.
Direct video-to-vector embedding skips transcription entirely—Twelve Labs but self-hosted.
1-bit weights matching 8B model performance while running 132 tokens/sec on M4 Pro.
Semantic-type compiler solves AI chart reliability better than raw Vega-Lite specs.
Very low latency speech to text, intent recognition, and text to speech, for building voice agents and interfaces
Beats Whisper v3 accuracy on $100K budget; shipping on six platforms now.
On-device, real-time multimodal AI. Have natural voice and vision conversations with an AI that runs entirely on your machine. Powered by Gemma 4 E2B and Kokoro.
Runs Gemma 4 E2B and Kokoro TTS locally with barge-in and vision.
Talk to your Mac, query your docs, no cloud required. On-device voice AI + RAG
Custom Metal shaders beat llama.cpp and MLX—1.67x faster on M4 Max.
Fine-tune Gemma 4 and 3n with audio, images and text on Apple Silicon, using PyTorch and Metal Performance Shaders.
Only Apple Silicon toolkit streaming GCS data during audio fine-tuning without OOM.
Screeps-style RTS where LLMs code their way to victory, real iterative learning.
NCAs that heal when damaged, now at HD resolution with implicit neural decoders.
4064 projects