AI/ML●Mid
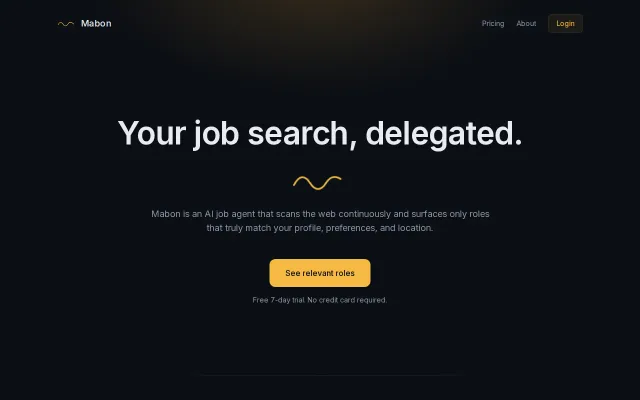
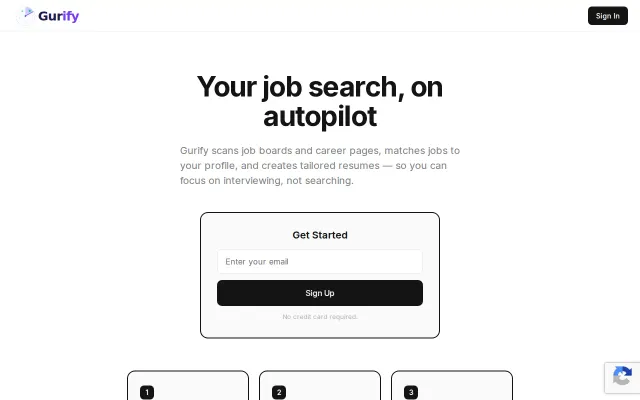
Mabon – AI agent that finds jobs continuously and shows strong matches
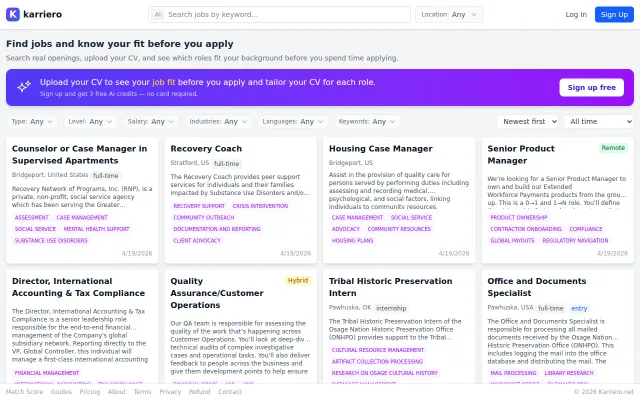
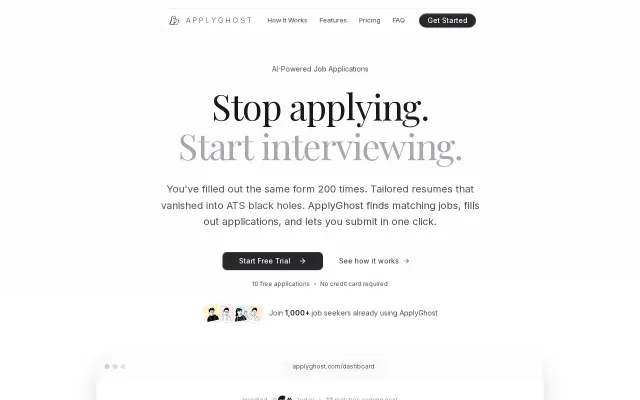
AI job agent when Otta, LinkedIn alerts, and Simplify already do this.
Ship It
luckystrike
311mo ago
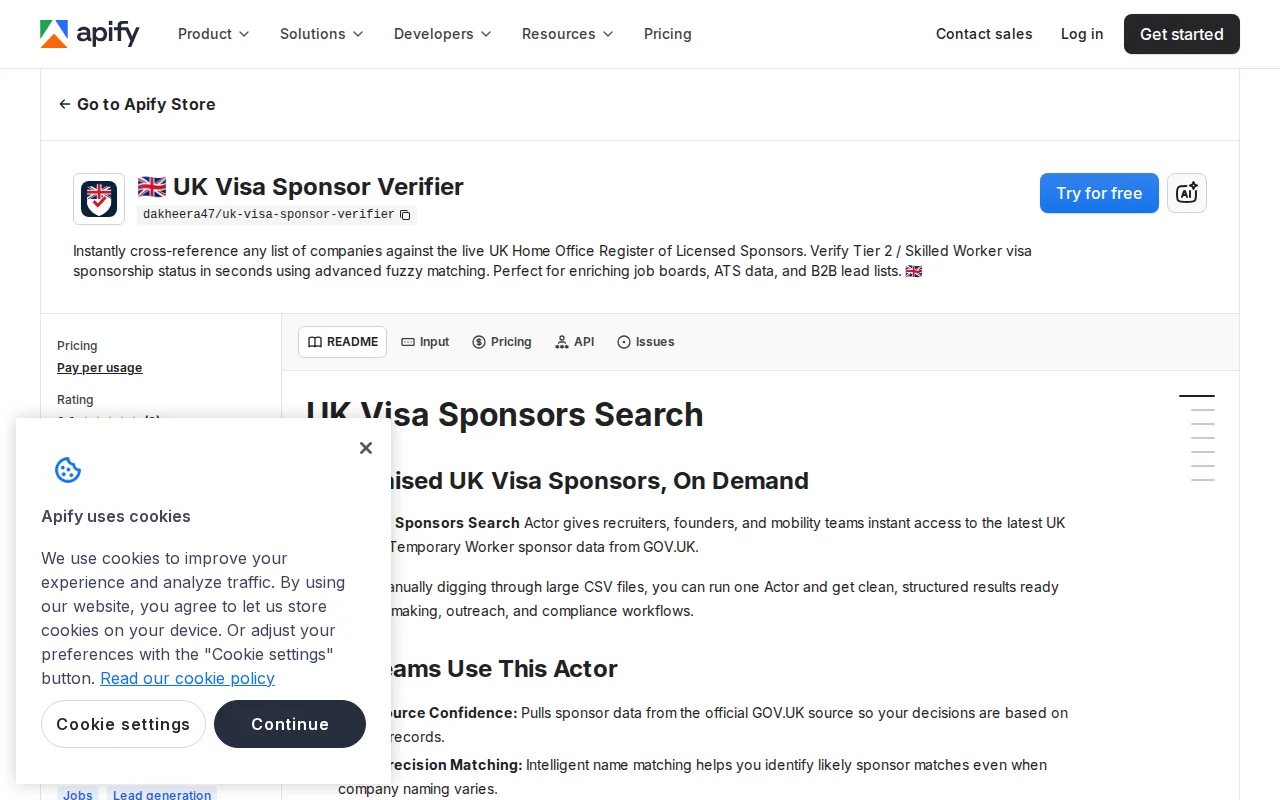
Solves UK visa sponsorship matching where exact-string matching fails completely.
Job boards, recruiters, ATS platforms, mobility teams managing visa sponsorship verification
Manual CSV joins · Crunchbase name matching APIs
I’ve been working on job application pipelines and kept hitting a massive data friction point: reliably filtering out UK companies that legally cannot sponsor international workers.
The UK Home Office publishes a constantly updating CSV of licensed sponsors. The problem is, the data is practically useless for standard database joins. A job board might list a role at "Acme", but the government registry lists "Acme Technologies Holdings Limited".
If you run an exact-string match or a basic ILIKE against a scrape of 10,000 Indeed or LinkedIn jobs, your false-negative rate is massive.
I wrote a TypeScript-based matching engine to solve this. Here is the pipeline:
Dynamic Ingestion: It bypasses the Gov.uk dynamic routing to pull the raw, multi-megabyte CSV directly into memory. No stale database records.
Text Normalization: I built a custom parser to strip out standard corporate suffixes ("ltd", "plc", "llp", "t/a", etc.) and handle the weird punctuation and localized encodings that break standard scrapers.
Fuzzy Scoring: It runs an optimized Levenshtein distance algorithm over the in-memory array to output a 0-100 confidence score for the match.
Initially, I built this with a persistent local cron scheduler (node:fs) for an open-source job ops project. But to make it scalable for batch processing, I ripped out the local caching and deployed it as an ephemeral Docker container. It spins up, processes an array of thousands of scraped companies entirely in-memory in a few seconds, pushes a clean JSON dataset of verified sponsors, and dies.
If you are building a job aggregator, an ATS, or a lead-gen pipeline and don't want to waste a weekend writing your own corporate-suffix normalization logic, I hosted the serverless endpoint here: https://apify.com/dakheera47/uk-visa-sponsor-verifier
I'd love any feedback on the text normalization approach, or to hear if anyone knows of specific edge cases in the Home Office data formatting that I might have missed.
AI job agent when Otta, LinkedIn alerts, and Simplify already do this.
Yet another AI job matcher in a sea of LinkedIn and Otta clones.
Yet another AI job matcher when LinkedIn, Indeed, and Jobscan already do this.
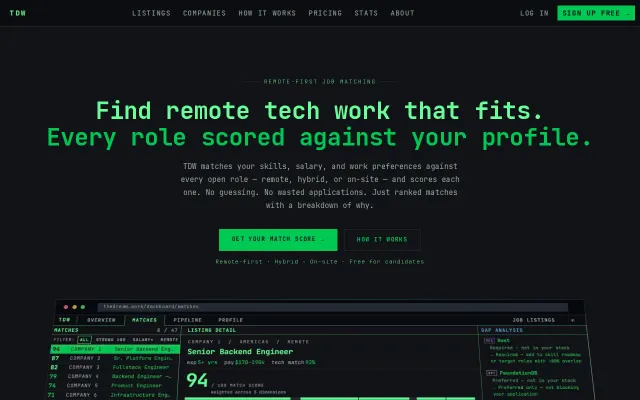
Scores job matches across 5 dimensions with transparent breakdowns.
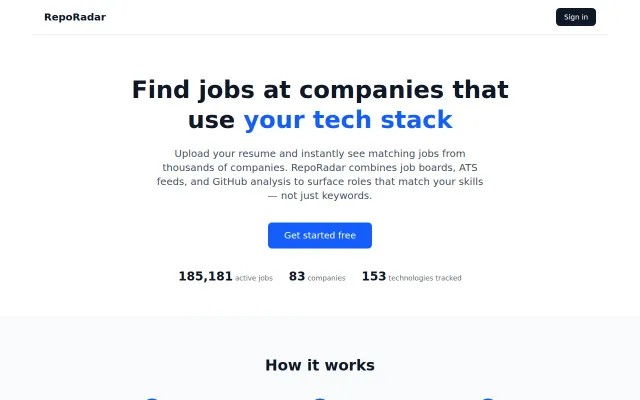
GitHub company tech detection is clever, but job boards are saturated.
AI-matched job auto-apply targeting quality over spray-and-pray. Competes with Rocketfy, Talently.