AI/ML●●Solid
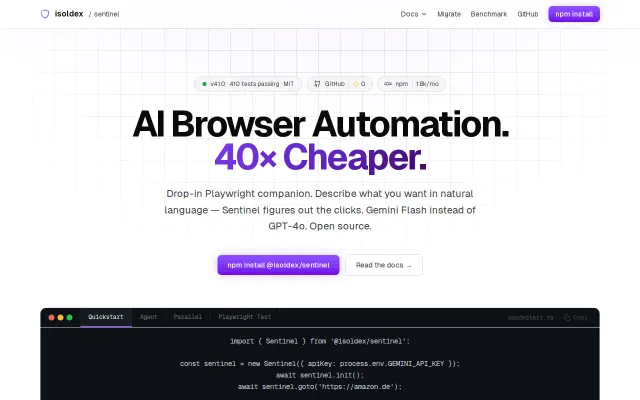
Sentinel – LLM browser automation using 10x fewer tokens
Token efficiency beats Stagehand — 2-5k vs 29-51k per action with cached selectors.
Solve My ProblemSlick
isoldex
101mo ago
The write-up zeroes in on a concrete, painful failure mode: MCP setups streaming full DOMs and logs into models and burning token budgets. It shows how playwright-cli keeps browser state external and emits compact element references and YAML flows you can replay into npx playwright test — a realistic pattern for long agent sessions. Valuable practical guidance for teams already on Playwright, but it's an explainer, not a new system you can drop in without plumbing.
Test automation engineers, frontend/backend developers using Playwright, and teams building AI agents for browser automation
That burns tokens, collapses context, and makes long sessions unreliable.
Meanwhile, default Playwright reports start to struggle once you have more than a few dozen e2e tests, so teams drown in HTML reports and flaky failures instead of clear patterns.
The insights at https://testdino.com/blog/playwright-cli/ explores how Microsoft’s playwright-cli keeps browser state external, returns only compact element references and YAML flows, and works with normal npx playwright test plus smarter reporting, so both agents and humans stay fast, cost aware, and predictable.
Token efficiency beats Stagehand — 2-5k vs 29-51k per action with cached selectors.
Browser automation MCP for one Indian grocer; interesting proof-of-concept, zero production use case.
JSON recovery fixes malformed LLM output when Firecrawl and JinaAI fail on nested schemas.
Replaces manual Playwright scripting, but Claude-generated tests and GitHub Copilot already cover this.
Curated Playwright repo list, but remove.bg-level: a solved problem in a crowded space.
Auto-translates docs as you push—zero YAML, no traditional translation platform overhead.