Developer Tools●●●Banger
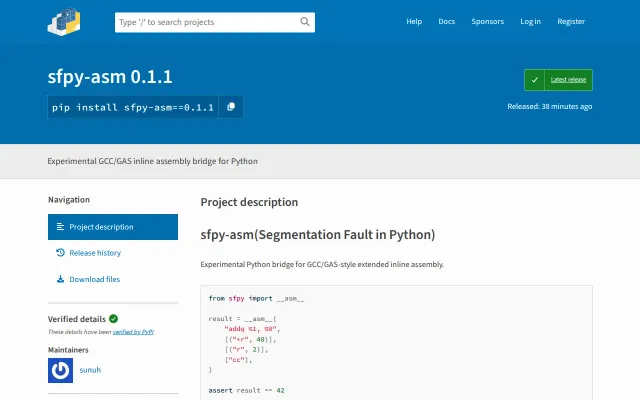
Experimental GCC/GAS inline assembly bridge for Python
Inline assembly in Python without C extensions - genuinely novel approach.
WizardryNiche GemBig Brain
sunuhwang
2022d ago
AI-generated x86-64 assembly vs GCC -O3 on production kernels. 4.8-6.3x on base64, verified with 300K fuzz iterations.
PSHUFB nibble trick beats GCC's lookup table by 4.8–6.3x on base64; reproducible fuzz methodology.
Low-level systems programmers, compiler engineers, AI researchers
Superoptimizer (classical) · STOKE (superoptimization tool)
Inline assembly in Python without C extensions - genuinely novel approach.
PTX kernel generation is rare, but 'self-improving' claims need verifiable benchmarks.
Dual Zig and C kernel implementations for comparing low-level language tradeoffs on x86.
Raw x86-64 assembly HTTP server with a bespoke triple-thread architecture.
Well-reasoned three-tier architecture, but lacks reference implementations and adoption proof.
A 44KB suite replacing standard coreutils by ditching libc and heap entirely.