Security●●Solid
PromptSonar – Static analysis for LLM prompt security
Static scanner catches prompt injections in code before runtime, unlike runtime guards.
Solve My ProblemShip It
meghal86
102mo ago
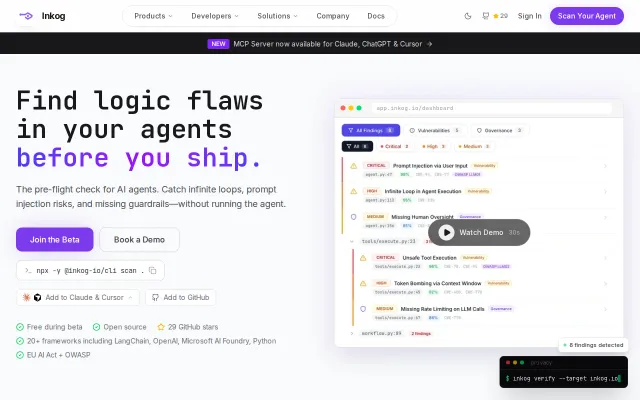
Scan your LLM-powered applications for authorization gaps, leaked credentials, missing rate limits, prompt injection risks, and other security issues — before they reach production.
Purpose-built LLM security linter covers OWASP Top 10, but static analysis has inherent blind spots.
Backend developers, DevSecOps engineers, LLM application builders
Semgrep · Snyk Code · GitHub CodeQL
I built llm-authz-audit because I kept seeing the same security issues in LLM-powered applications: API keys hardcoded next to OpenAI calls, FastAPI endpoints serving chat completions with zero auth, user input concatenated straight into prompts, and shared conversation memory with no session isolation.
These aren't hypothetical — they're patterns I found repeatedly across open-source LLM projects and production codebases.
What it does:
It's a static analyzer (think eslint/semgrep but purpose-built for LLM security) that scans Python, JavaScript, and TypeScript codebases for authorization and security gaps. It ships with 13 analyzers and 27 rules covering the OWASP Top 10 for LLM Applications:
- Prompt injection risks (unsanitized input in prompts, missing delimiters) - Hardcoded API keys (OpenAI, Anthropic, HuggingFace, AWS, generic) - Unauthenticated LLM endpoints (FastAPI, Flask, Express) - LangChain/LlamaIndex tools without RBAC - RAG retrievals without document-level access controls - Over-permissioned MCP server configs - Shared conversation memory without user scoping - Missing rate limiting, audit logging, output filtering - Credentials forwarded to LLM via prompt templates Would love feedback from anyone building or securing LLM applications.
Static scanner catches prompt injections in code before runtime, unlike runtime guards.
Isolated LLM with no tools or memory makes prompt injection hit a dead end.
Catches infinite loops and injection risks without running the agent, but Snyk+Semgrep+manual review already covers this.
First open-source scanner for AI agent skill supply-chain attacks.
Yet another LLM ops layer when LangSmith, Helicone, and Braintrust already exist.
Heuristic-based shields beat LLM-in-the-loop detectors on speed, but Lakera Guard already owns this space.