Developer Tools●●●Banger
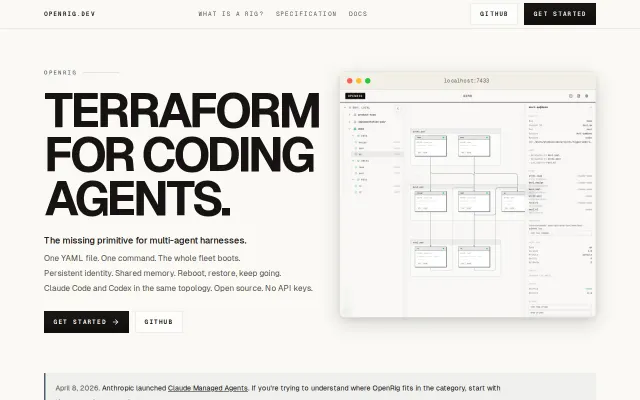
OpenRig – a control plane for multi-agent coding topologies
Terraform for agent fleets solves the terminal sprawl problem nobody else addressed.
Big BrainZero to OneSolve My Problem
mschwarz
6822d ago
Define AI agent roles in YAML and run them anywhere: CLI, API server, or autonomous daemon
You write one YAML file and get a working agent with RAG, persistent memory, auto-registered tools (search_documents, remember, recall), and an OpenAI-like HTTP endpoint — three commands: ingest, run, serve. The no-code config approach is a neat product decision: it removes the typical wiring pain of LangChain-style setups and makes an agent deployable locally or in Docker in minutes. It isn’t the first agent framework, but the YAML-first + API compatibility combo is a practical, approachable execution that developers will actually try.
Backend developers, ML engineers, dev teams and hobbyists who want to prototype and deploy AI agents without writing glue code
apiVersion: initrunner/v1 kind: Agent metadata: name: acme-support description: Support agent for Acme Corp spec: role: You are a support agent for Acme Corp. model: provider: openai name: gpt-4o-mini ingest: sources: - ./docs/*/.md - ./knowledge/*/.pdf memory: max_memories: 1000
initrunner ingest agent.yaml initrunner run agent.yaml -i initrunner serve agent.yaml --port 3000
Three commands: ingest your docs, test interactively, serve over HTTP. The agent gets search_documents, remember, and recall tools auto-registered. No code to wire up.
Point Open WebUI or any OpenAI client at localhost:3000/v1 and you have a full chat interface over your knowledge base with persistent memory across sessions.
Built on PydanticAI, SQLite + sqlite-vec. No Redis, no Postgres, no infra.
curl -fsSL https://initrunner.ai/install.sh | sh
Terraform for agent fleets solves the terminal sprawl problem nobody else addressed.
Structured memory layers for agents—but vector search already solves this problem.
Another open-source AI agent—self-improvement is just keyword-matched JSON rules.
Mimir hooks into Claude Code lifecycle events so agents can 'mark' facts (e.g., "API uses snake_case") into a DuckDB-backed memory and RAG pipeline, then auto-injects that context as additionalContext for later agents. It's a pragmatic, well-scoped solution to the annoying problem of agent amnesia — very useful if you run agent swarms, but its impact is limited by Claude Code adoption and the need for the surrounding infra (BGE keys, hooks).
Claude Code agent orchestrator with Excel/PowerPoint automation, but unproven execution and sparse documentation.
Compaction tree cuts context from 100K tokens to 3K without losing memory.