Developer Tools●●Solid
Perstack – Containerized harness, 5 tests with full logs and API cost
Containerized agent harness with TOML config instead of code-wired frameworks.
Big BrainShip It
FL4TLiN3
202mo ago
Test harness for voice agents. Import from Retell, VAPI, Bland, LiveKit. Run autonomous simulations. Evaluate with LLM judges.
Unified test harness for voice agents across Retell, VAPI, LiveKit, Bland with LLM scoring.
Voice AI engineers and product teams building agents across multiple platforms
Postman (API testing abstraction) · Playwright (cross-framework test standardization) · LoadImpact (performance testing across variants)
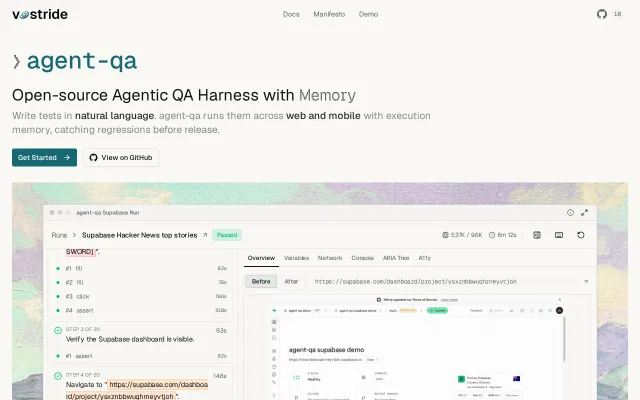
voicetest is an open source (Apache 2.0) test harness that works across voice AI platforms. You import your agent graph from any supported platform (or define one from scratch), write test scenarios with expected behaviors, and voicetest simulates conversations and evaluates them with LLM judges that score each turn 0.0-1.0 with written reasoning. It also ships global compliance evaluators for things like HIPAA, PCI-DSS, and brand voice consistency. The core abstraction is an AgentGraph IR that normalizes across platform formats, so you can convert between Retell, VAPI, LiveKit, and Bland configs and test them all the same way.
Quick start:
``` uv tool install voicetest voicetest demo --serve ```
That gives you a web UI at localhost with a sample agent, test cases, and evaluation results you can poke at. There's also a CLI, a TUI, and a REST API. It integrates into CI/CD with GitHub Actions, uses DuckDB for persistence, and includes a Docker Compose dev environment with LiveKit, Whisper STT, and Kokoro TTS. If you have a Claude Code subscription, voicetest can pass through to it instead of requiring separate API keys for evaluation.
GitHub: https://github.com/voicetestdev/voicetest Docs: https://voicetest.dev API reference: https://voicetest.dev/api/
Containerized agent harness with TOML config instead of code-wired frameworks.
Deterministic agent benchmarking with strict validation—unlike SWE-Bench, measures whether agents actually operate.
Multi-turn adaptive testing finds agent failures static benchmarks miss, but eval space is crowded.
Iteratively improves agent harnesses from 67% to 87% on tau-bench using production traces.
Manifest-driven agents with eval feedback loops when most harnesses are prompt-only.
Self-healing tests that remember UI changes so you stop fixing broken selectors.