Developer Tools●●Solid
GPU multi-agent war simulation
GPU-vectorized PPO arena with thousands of agents, but emergent behavior research remains niche.
Big BrainWizardryRabbit Hole
luthor190397
105mo ago
H.E.I.M.D.A.L.L looks at fleet telemetry and gives you natural-language insights. GPU data loading (cuDF), local LLM inference (Gemma 2), and production NIM on GKE. Open the notebooks, run cells, get answers! Quick start should not take longer than 10 minutes and the T4 path is completely free!
Combines GPU-first data ingest (cuDF + UVM) with format-aware inference choices (GGUF for local Gemma 2, TensorRT for production) and ships three runnable notebooks — including a full NIM-on-GKE deployment — so you can benchmark pandas vs cuDF and walk through local-to-cloud inference. Clever and practical for teams that actually need to scale telemetry queries, but expect non-trivial ops work, vendor lock-in to NVIDIA/GCP tooling, and cloud costs to reproduce the full stack.
Data engineers, ML/robotics engineers, and SREs working with large fleet telemetry who want GPU-accelerated analytics and LLM-driven querying
GPU-vectorized PPO arena with thousands of agents, but emergent behavior research remains niche.
Former maintainers revived abandoned OpenSfM with C++ rewrite and OpenCL GPU acceleration.
2x prefill speedup on 12k+ token contexts by treating GPUs like a production line.
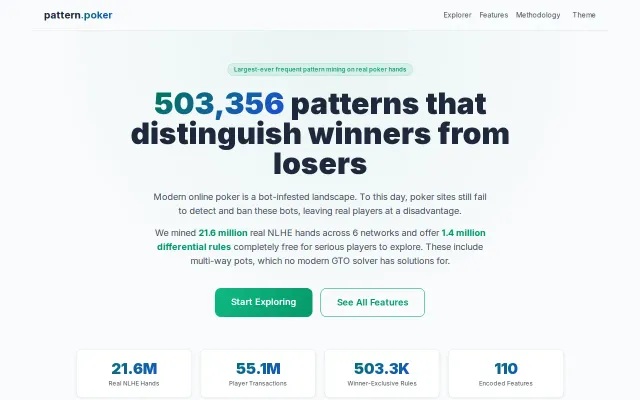
GPU-accelerated pattern mining from protein research repurposed for poker hand analysis.
Direct2D GPU PDF renderer with CPU fallback, but alpha-stage and Windows-only.
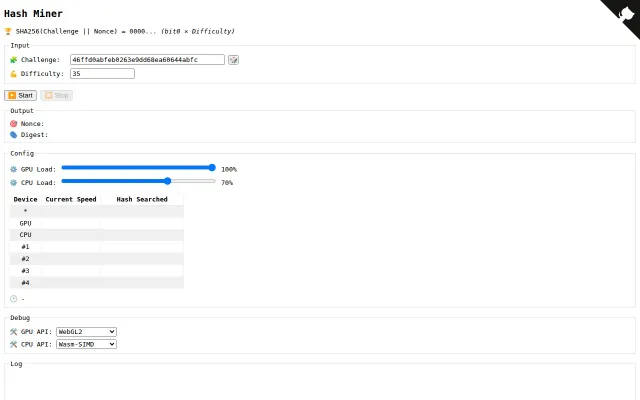
WebGPU and WASM-SIMD hash mining in browser with per-device load controls.