Developer Tools●●●Banger
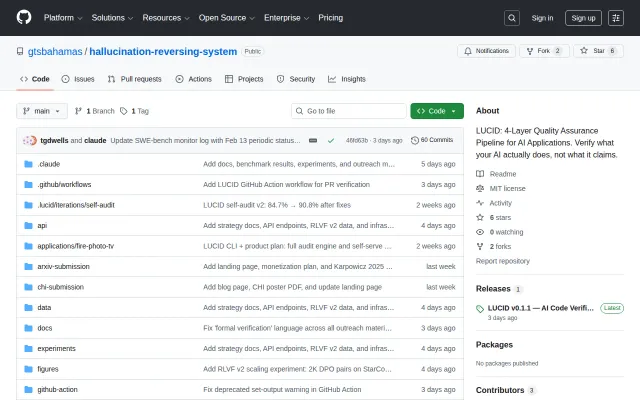
Lucid – Catch hallucinations in AI-generated code before they ship
Treats hallucination as inevitable, verifies claims instead of suppressing generation.
Big BrainShip ItSolve My Problem
jordanappsite
405mo ago
Training can't fix hallucinations—verify externally instead. Backed by surprising RLVF data.
Engineers shipping AI-assisted code who want hallucination detection
Copilot guardrails · Code2Prompt verification modes
The starting point was a finding that surprised me: when we tried training verification directly into models using RLVF (Reinforcement Learning from Verification Feedback), more training data made the model worse. 120 curated pairs hit 91.5% accuracy. 2,000 pairs collapsed to 77.4%. The model's training loss kept decreasing while eval performance cratered. This isn't a tuning problem. Verification cannot be internalized.
So we built an external layer. Assay extracts the implicit claims code makes ("this handles null input," "this query is injection-safe," "this validates auth tokens") and verifies each one against the actual implementation. It's not a linter, not another LLM-as-judge — it's structured claim extraction followed by adversarial verification.
Results validated against real test suites (not LLM judgment): - HumanEval: 100% pass@5 (164/164) — baseline was 86.6% - SWE-bench: 30.3% (91/300) vs 18.3% baseline — +65.5% - LVR pilot: Found 23 real bugs (2 critical) in a production ERP system, verified 354 claims - LLM-as-judge actually regresses at k=5 (97.2% vs our 100%) because it hallucinates false positives
Ships as a GitHub Action for PR verification, or try it: npx tryassay assess /path/to/your/project
Public repo (the URL above points to our private research repo): https://github.com/gtsbahamas/assay-verify
GitHub Action: uses: gtsbahamas/assay-verify/github-action@main
Treats hallucination as inevitable, verifies claims instead of suppressing generation.
Six endpoints for grounding AI, but RAG solutions already handle this.
Catches AI agents lying about test results by verifying against actual git and filesystem state.
Builds a master career profile so AI doesn't miss your best experience.
Fact-checking extension for AI claims when Pino and others already exist.
Another signed claim spec when JWT and Verifiable Credentials already exist.