Developer Tools●●Solid
Security MCP expose your org's policies and paved roads to agents
Security policies as an API for coding agents — timely for the agent economy.
Solve My ProblemShip It
prahathess
1010d ago
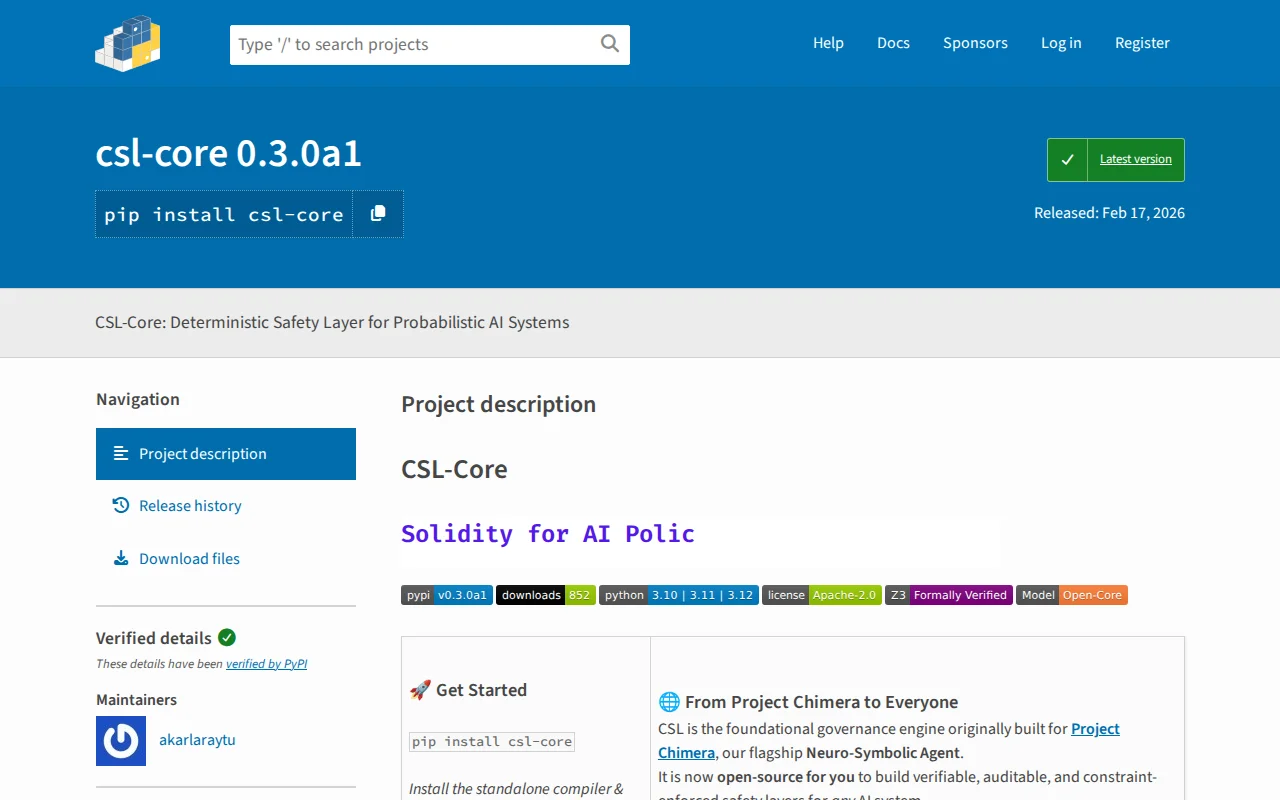
Mathematically verified policies enforced outside the model—formal proof replaces prompt engineering.
AI safety teams, enterprise deploying constrained AI agents, compliance-heavy orgs
Anthropic's Constitutional AI · Policy-as-code tools like OPA · Guard rails and gate frameworks
verify_policy: Z3 formal verification in one call
simulate_policy: test any JSON input, get ALLOWED/BLOCKED
explain_policy: human-readable breakdown of any policy
scaffold_policy: describe what you want in English, get a CSL template
This means you can do this from Claude Desktop or Cursor:
"Write me a policy that blocks transfers over $5000 for non-admin users"
→ scaffold generates a CSL template
→ verify proves it has no contradictions
→ simulate tests your edge cases
→ all without leaving your editor
The full loop: From English description to mathematically verified, runtime-enforced policy; happens inside your AI assistant.
Why not just prompt the LLM to enforce rules? We benchmarked GPT-4o, Claude Sonnet 4, and Gemini 2.0 Flash as guardrails with a hardened system prompt. Every model was bypassed by at least one attack (context spoofing, multi-turn role escalation, unicode homoglyphs). CSL-Core blocked all of them; because the LLM never touches the enforcement layer.
Setup:
pip install "csl-core[mcp]"
Claude Desktop config:
{
"mcpServers": {
"csl-core": {
"command": "csl-core-mcp"
}
}
}
Or with Docker:
docker build -t csl-core-mcp .
docker run -i csl-core-mcp
GitHub: https://github.com/Chimera-Protocol/csl-core
Listed on awesome-mcp-servers:
https://github.com/punkpeye/awesome-mcp-servers
Previous Show HN discussion: https://news.ycombinator.com/item?id=46963250
Would love feedback, especially from anyone building agentic systems where safety guarantees matter.
Security policies as an API for coding agents — timely for the agent economy.
Harness-level command interception blocks dangerous operations, not just prompt-based safety.
Finally, shared memory across Claude Desktop and Cursor without cloud accounts.
Yet another MCP wrapper, but Ultralytics users will find this convenient.
Trust scores and CVE checks beat manual MCP server hunting.
Claude Code CLI agents on visual canvas with Director/Planner meta-agents steering execution.