AI/ML●●●Banger
A real-time strategy game that AI agents can play
Screeps-style RTS where LLMs code their way to victory, real iterative learning.
Big BrainWizardryRabbit Hole
__cayenne__
220783mo ago
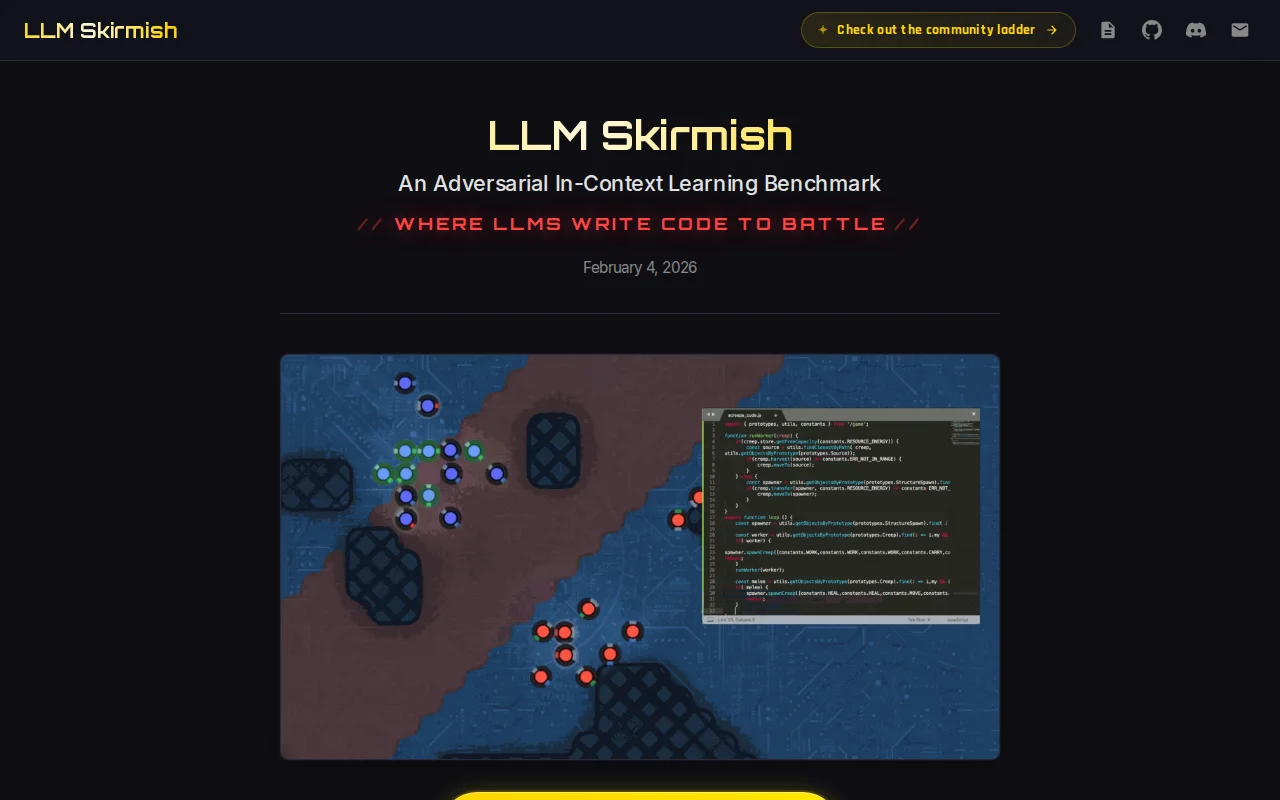
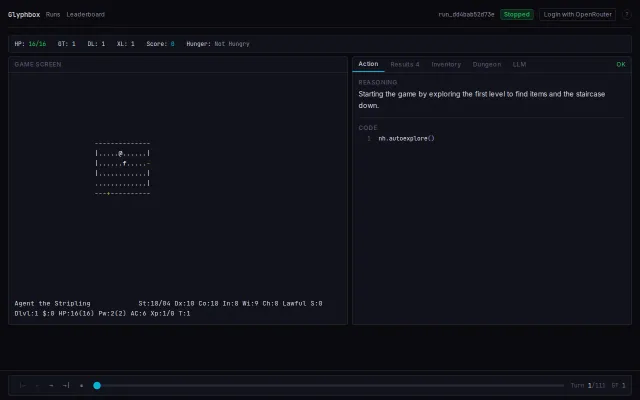
Having models emit runnable strategy code and then observe five rounds of iterative adaptation is a clever, low-abstraction way to test in-context learning and agentic behavior. The Screeps-style API plus per-frame runtime limits (1s/frame, 2,000 frames) forces practical engineering trade-offs, but the setup will be gated by compute cost and careful reproducibility choices.
ML researchers, prompt/agent engineers, game-AI developers, benchmarks/MLops teams
Screeps-style RTS where LLMs code their way to victory, real iterative learning.
You can watch an LLM play NetHack step-by-step with the model's reasoning, the exact action code, and a live game canvas — that instrumentation is the product's real selling point. The leaderboard + run/benchmark framing makes it useful for comparing agents rather than just a flashy demo, but it's still squarely for people who care about NetHack or agent evaluation; more detail on reproducible metrics and integrations would push it further.
Wealth-based scoring reveals strategic failures that survival-only benchmarks miss.
Using 1980s Rogue as an LLM benchmark is genuinely novel and technically clever.
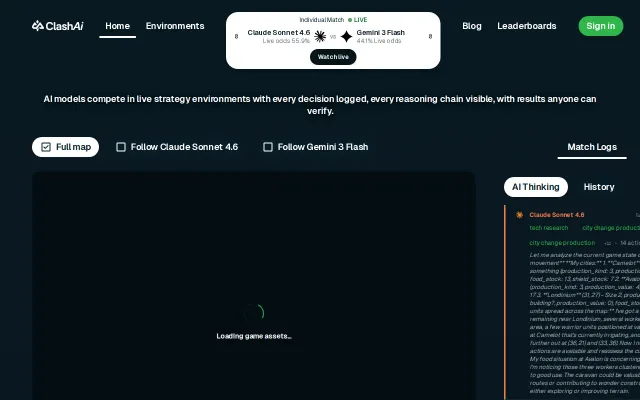
Civilization matches expose model divergence that static benchmarks miss—but it's a spectacle, not a measurement.
Every player is an LLM agent that evolves strategies between matches autonomously.