Productivity●●Solid
arxiv-digest: Daily robotics paper scouting for OpenClaw and Zotero
LLM-filtered arXiv digest with Zotero PDF sync for robotics researchers.
Niche GemBig Brain
tb5z035i
104mo ago
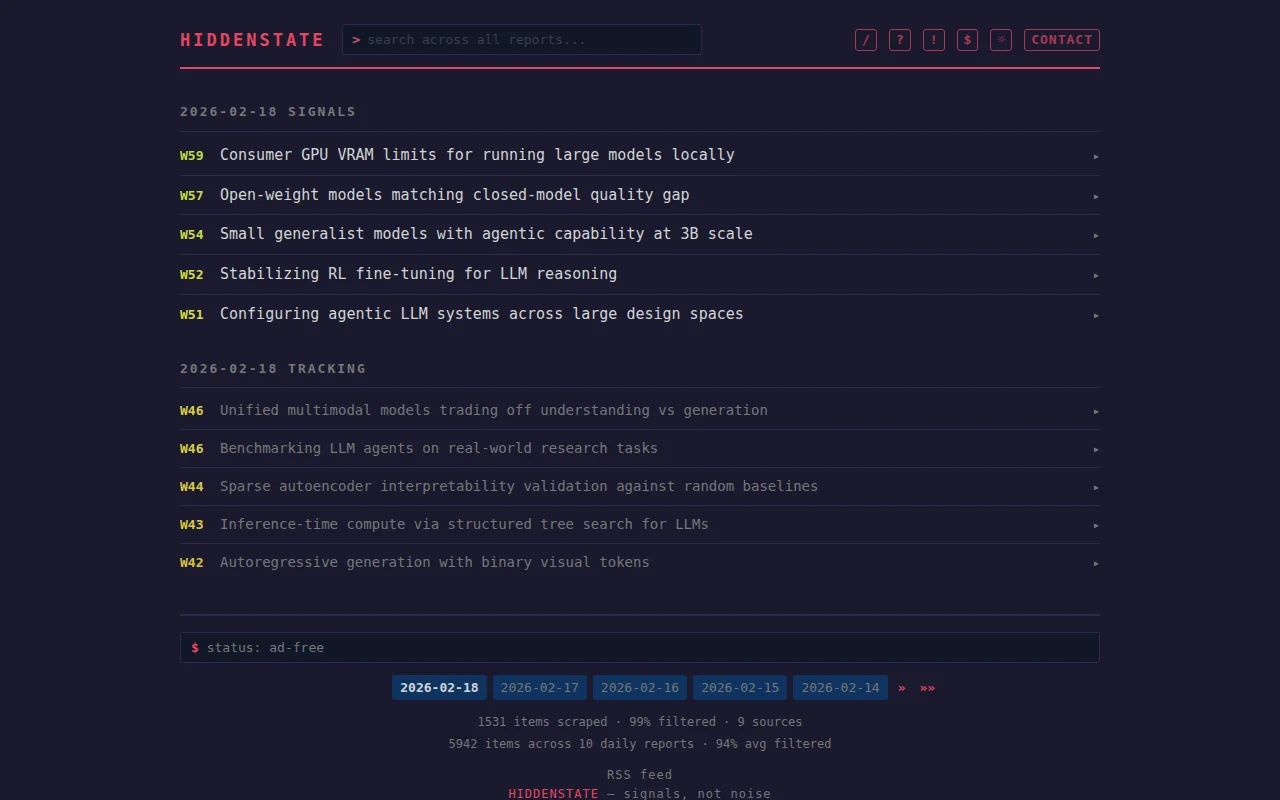
Clustering by the specific technical constraint being attacked — not by topic — and scoring each signal on convergence, implementation evidence, engagement and significance is a neat, high-signal trick for surfacing research trends. It smartly dedupes org noise and ingests many sources, though using Claude as a clustering black box means the scoring pipeline could use clearer auditability or export hooks for skeptical researchers.
ML researchers, research engineers, AI product leads, PhD students and 'trend scouts' who need to spot convergent signals across many sources
Example from this week; 7 independent VLA papers dropped within 24 hours from 9 different orgs. Xiaomi, GigaBrain, RISE, all attacking sim-to-real transfer for robotic manipulation. None coordinating. That kind of convergence is hard to spot unless you're reading everything.
Each mechanism gets a 0-100 score across convergence, implementation evidence, engagement, and significance. Orgs are deduplicated so a single lab posting on five platforms doesn't inflate the signal.
Python, SQLite, Claude for clustering, Cloudflare Pages. Free, no tracking. Looking for any and all feedback and thoughts! Cheers!
LLM-filtered arXiv digest with Zotero PDF sync for robotics researchers.
Four-layer summaries with counter-arguments beat simple TL;DR generators.
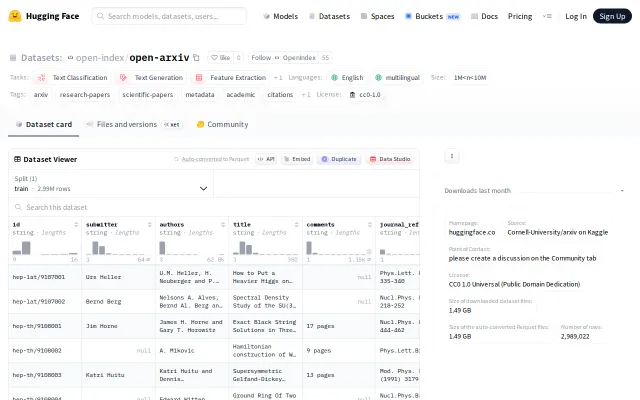
Pre-cleaned ArXiv metadata in Parquet saves hours of ETL pipeline work.
Hybrid search over 5,600 papers when Elicit and Semantic Scholar already exist.
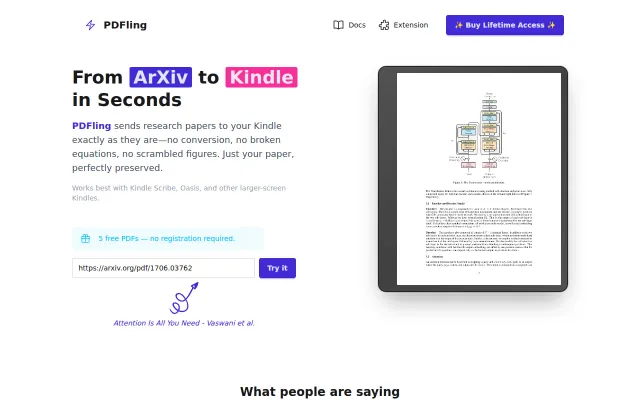
PDFs to Kindle without scrambled equations—solves one specific pain point elegantly.
Automates 3Blue1Brown-style Manim visuals for any arXiv paper URL.