SaaS●●Solid
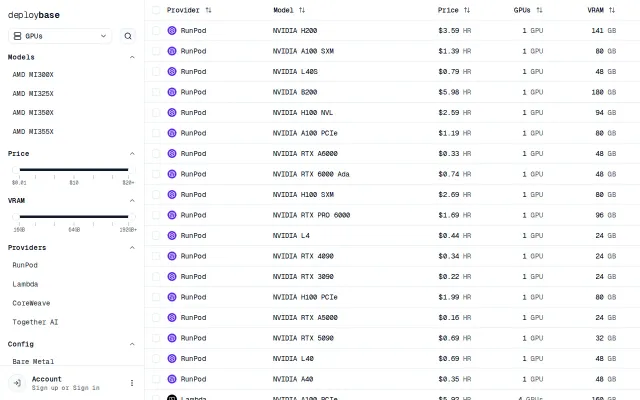
Deploybase – Compare GPU and LLM pricing across all major providers
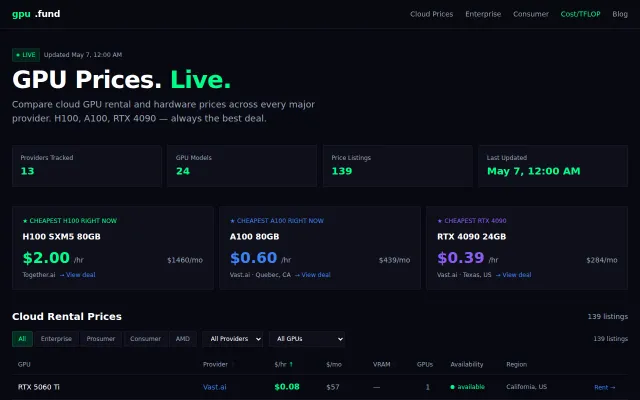
Real-time GPU pricing aggregator, but existing tools like Crusoe Dashboard already solve this.
Solve My Problem
grasper_
303mo ago
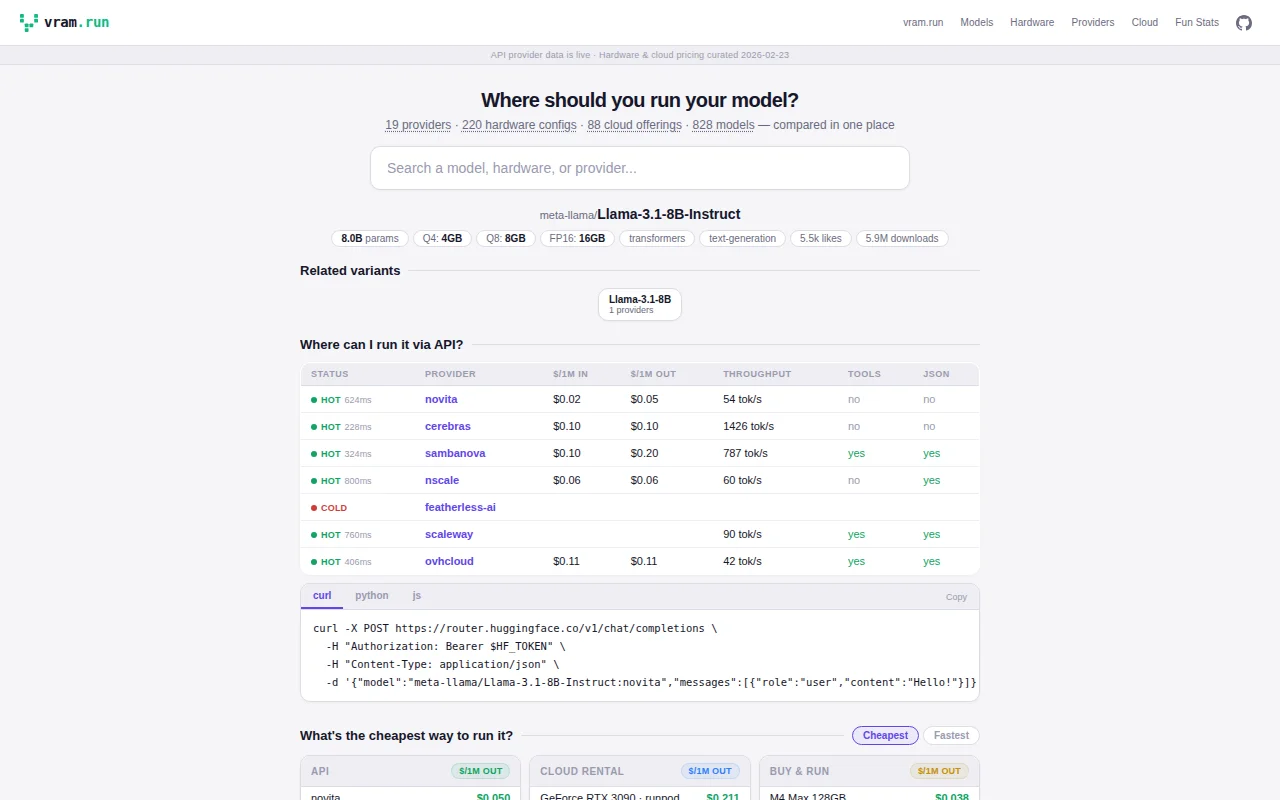
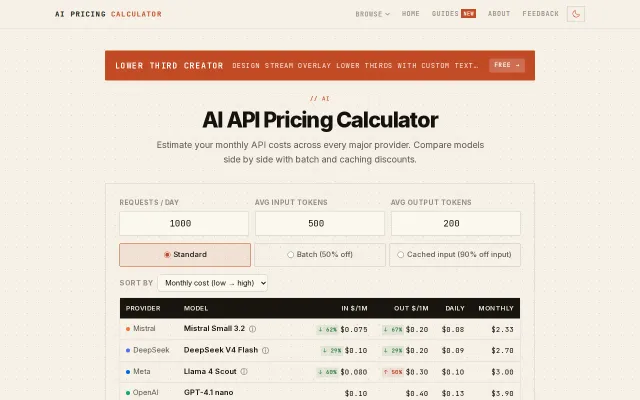
Single lookup table: cheapest way to run any model across APIs, GPUs, or cloud.
ML engineers, LLM product teams, cost-conscious inference users
LLM.report · OpenRouter pricing compare · LocalAI benchmarks
Real-time GPU pricing aggregator, but existing tools like Crusoe Dashboard already solve this.
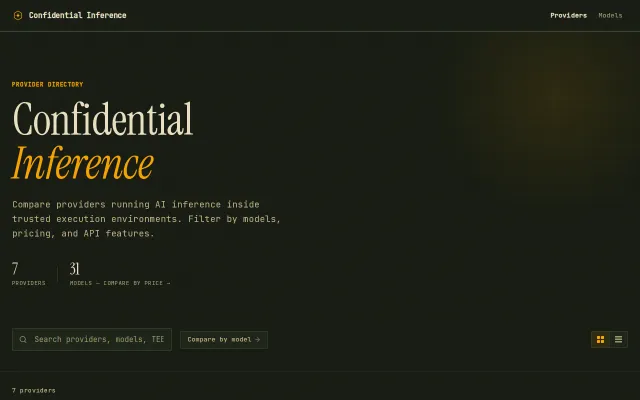
Scrapes 7 TEE inference providers and their pricing; semi-manual curation.
Yet another AI cost calculator in a sea of clones.
Finally a single tab to check H100 prices instead of opening ten provider dashboards.
Hardware-aware model bin-packing across mixed GPUs beats manual vLLM config.
Claude talks to RunPod/Lambda/Lambda/Vast — but needs working provider integrations to matter.