Developer Tools●Mid
A SQLite graph that captures why AI-generated code exists
Spec-heavy architecture for a problem Polarion already solves.
Niche Gem
enzo_ferrari
302mo ago
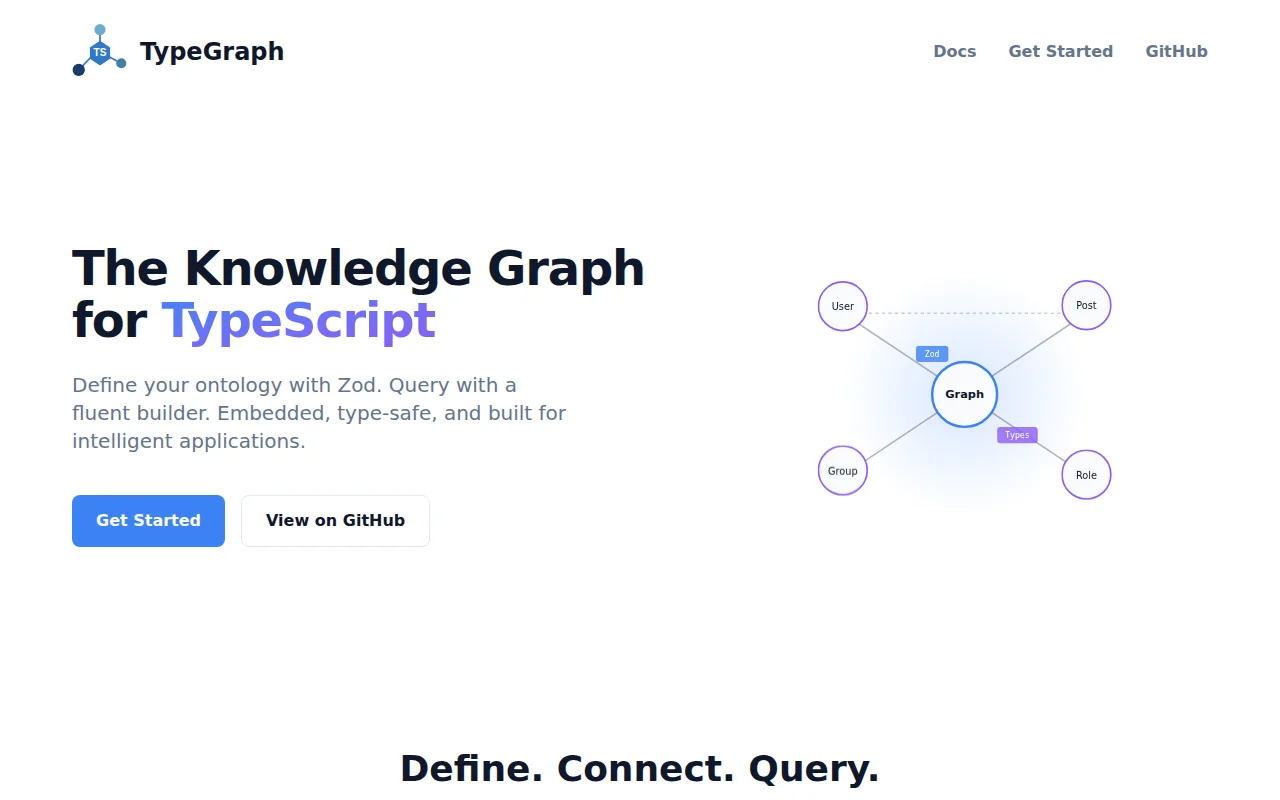
Graph semantics on Postgres without Neo4j infra overhead or hand-rolled boilerplate.
Developers building RAG systems, permissions models, recommendations, and knowledge graphs
Neo4j · ArangoDB · TigerGraph
After years of building knowledge graphs and other graphy things, I had the same issues whenever an application’s relationship modeling (permissions, RAG context, recommendations) outgrew standard ORMs: deploy a dedicated graph database (heavy ops, separate infra, data syncing headaches), or roll a graph-in-SQL implementation by hand.
I've hand-rolled enough of these to know the drill: same table structures, same traversal boilerplate, same performance surprises. I wanted graph semantics without graph infrastructure so I built TypeGraph as that pattern packaged as a library. It runs on anything from in-memory SQLite to a full Postgres cluster, using Zod for a single source of truth (driving your DB schema, API validation, and TS types).
You query it with a fluent builder that's fully typed through traversals:
const results = await store .query() .from("Person", "p") .traverse("worksAt", "e") .to("Company", "c") .whereNode("c", (c) => c.industry.eq("Tech")) .select((ctx) => ({ person: ctx.p.name, company: ctx.c.name, role: ctx.e.role, })) .execute();
Eject at any time and you're left with clean, well-structured SQL tables and nothing proprietary to untangle.A few things that set it apart from rolling your own:
* Ontology reasoning: subClassOf, implies, inverseOf — query for "Media" and automatically get Podcasts and Articles. Define "Admin implies Editor" and permission checks expand automatically.
* Vector + graph queries: combine embedding similarity search with graph traversal in one query. Uses pgvector on Postgres, sqlite-vec on SQLite.
* Incremental adoption: builds on Drizzle. Add graph capabilities to an existing project without replacing your ORM or migrating your database.
Where it works well: knowledge graphs for RAG (vector similarity + graph context), relationship-based access control, recommendations, social features, any domain where multi-hop relationships are core.
Where it doesn't: billions of edges (use a graph database), heavy graph algorithms like PageRank (use specialized tools), distributed graph processing.
Docs: https://typegraph.dev
GitHub: https://github.com/nicia-ai/typegraph/
Happy to answer questions about the design, implementation, or tradeoffs.
Spec-heavy architecture for a problem Polarion already solves.
Postgres + pgvector + MCP integration solves the AI amnesia problem better than vector DB silos.
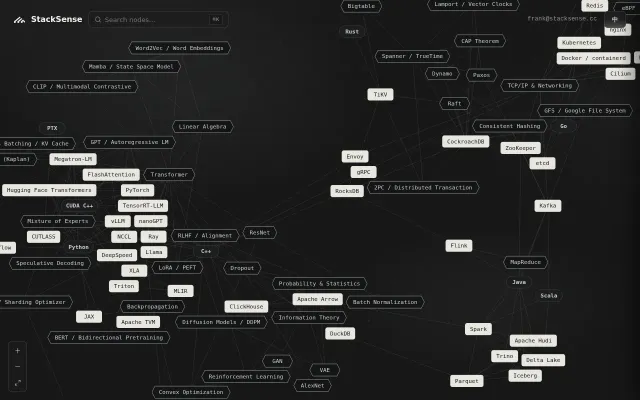
Massive interactive graph connecting LLMs to kernels, perfect for losing an afternoon.
Knowledge graph RAG for code when Cursor and Cody already own this space.
Visualizes business logic flows, not just dependencies, with Claude Code integration.
Markdown knowledge graph replaces scattered PLAN.md files with structured protocol.