Infrastructure●●Solid
PostgreSQL backup manager with BTRFS block-level deduplication
Gzip breaks dedup; this stores uncompressed snapshots on BTRFS for 85% savings.
Big BrainNiche Gem
giis
202mo ago
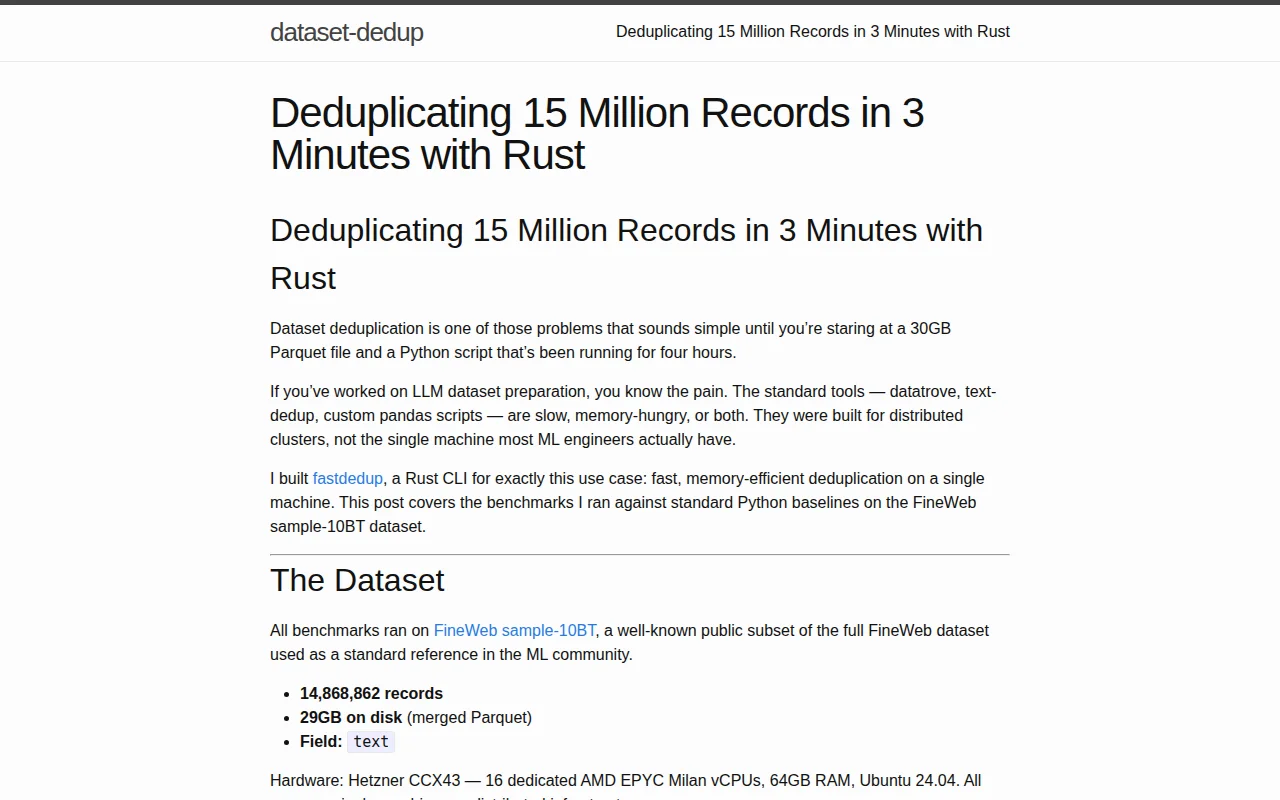
Bloom filter + AHash pipeline cuts exact dedup from 7:55 to 2:55, 688MB vs 21.9GB RAM.
ML engineers, data scientists preparing LLM datasets
DuckDB · datatrove · text-dedup
2:55 vs 7:55 wall clock (2.7x faster) 688MB vs 21.9GB peak RAM (32x less) Single core vs 4+ cores Duplicate counts match exactly (51,392 both ways)
Fuzzy dedup (MinHash + LSH) vs datatrove:
36:44 vs 3h50m+ — datatrove stage 1 alone ran for 3h50m and we killed it datatrove's bottleneck turned out to be spaCy word tokenization on every document before shingling. fastdedup uses character n-grams directly which is significantly cheaper 23GB vs 1.1GB RAM — this is a real trade-off, not a win. datatrove streams to disk; fastdedup holds the LSH index in memory for speed
Honest caveats:
Fuzzy dedup needs ~23GB RAM at this scale — cloud workload, not a laptop workload datatrove is built for distributed execution, tasks=1 isn't its intended config — this is how someone would run it locally Tiered storage to spill LSH index to disk is on the roadmap
Demo: https://huggingface.co/spaces/wapplewhite4/fastdedup-demo Repo: https://github.com/wapplewhite4/fastdedup Happy to answer questions about implementation or methodology.
Gzip breaks dedup; this stores uncompressed snapshots on BTRFS for 85% savings.
Backpressured pipeline with 60-80% dedup savings beats chatty multi-agent frameworks.
Tantivy full-text search with mmap'd index serves 85% of requests from cache in under 1ms.
Sits between logs and Datadog—eliminates retry noise, saves 60–90% ingestion volume.
Entropy-based context compression beats naive token stuffing, but the category is crowded.
Small 7k row dataset for media bias research when larger corpora already exist.