AI/ML●Mid
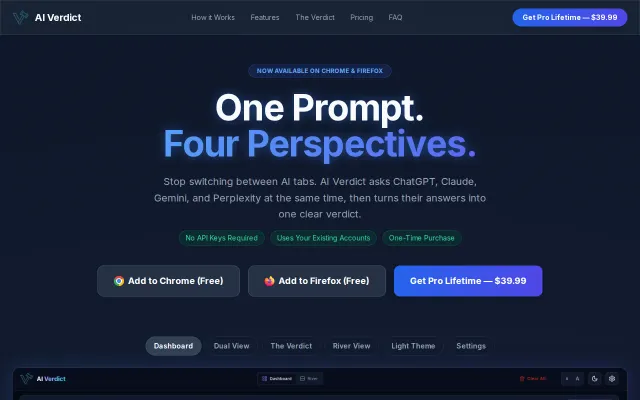
AI Verdict – Run ChatGPT, Claude, Gemini and Perplexity Side-by-Side
Multi-AI comparison extension when ChatHub and similar tools already exist.
SlickCrowd Pleaser
aiverdict
104d ago
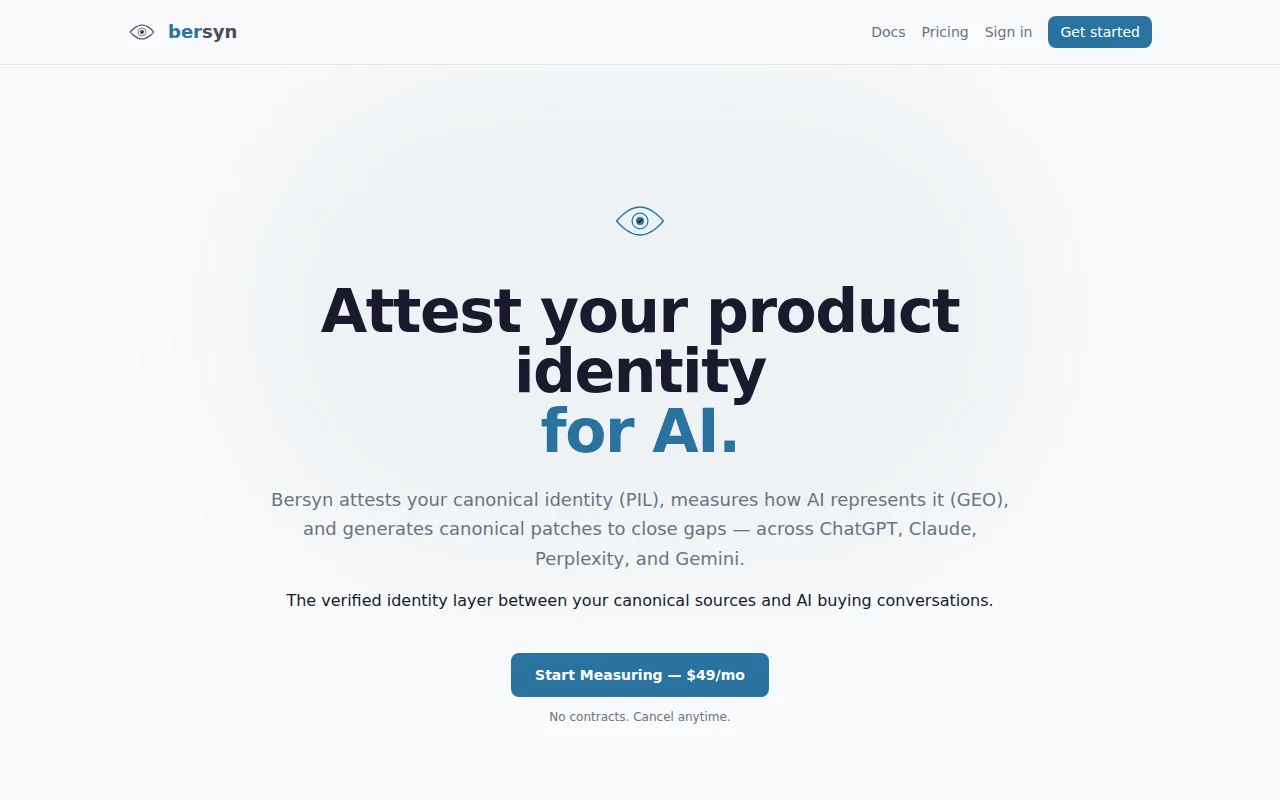
AI representation auditing for SaaS, but the category already has SEO/discovery tools.
B2B SaaS founders, marketing leaders concerned with AI search visibility
Semrush · Ahrefs · BrightEdge
Multi-AI comparison extension when ChatHub and similar tools already exist.
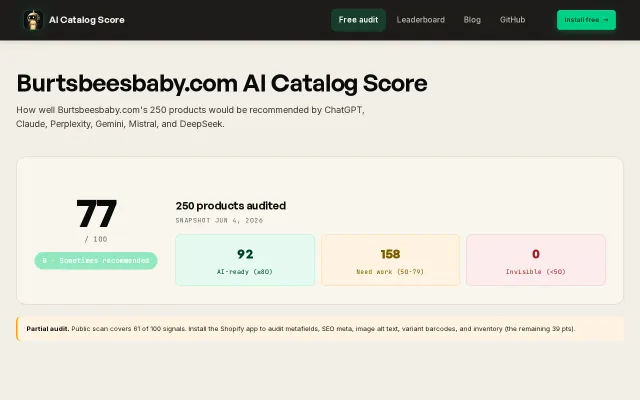
Scores product catalogs for AI agent visibility before this becomes a standard SEO requirement.
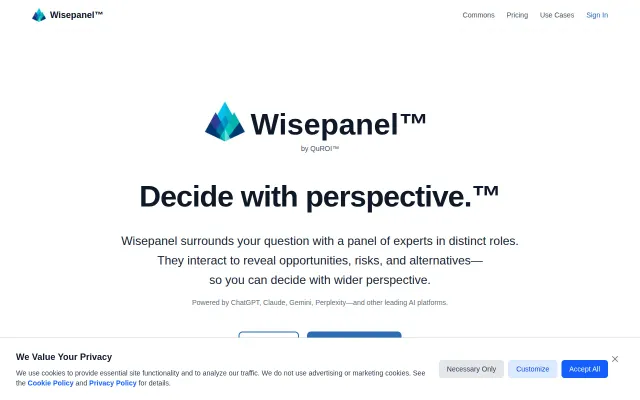
Assigning each LLM a distinct analytical role and letting them interact is the clearest differentiator here — the product sells the exchange, not a side‑by‑side dump. The landing copy and UI make the promise obvious, but there’s no visible detail on how models are orchestrated, how contradictions or hallucinations are reconciled, or what the UX for moderating the panel looks like in practice.
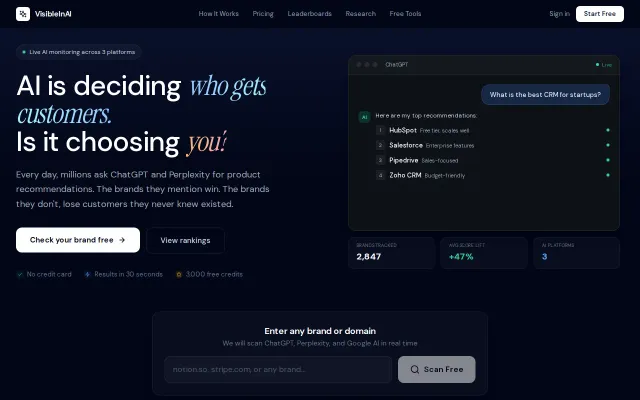
It treats LLM outputs as a new acquisition channel and backs that insight with real-time scans, an AI visibility score, alerts and auto-generated content aimed at sources LLMs trust (Reddit/Quora/Medium). The execution reads product-grade, but the landing leans on bold claims (human publishing network, +47% lift) with little methodological transparency and potential platform/ethics risk around gaming AI recommendations — I'd want more proof and clarity before committing budget.
Another AI memory wrapper when MemGPT and Recall already exist.
Tracks citations and sentiment across ChatGPT, Claude, Perplexity, Gemini and others, then surfaces gaps where competitors get mentioned but you don't (Battlemap) and prescribes concrete content edits (Hikoo Analyzer + Elevate). Smart product-market fit — GEO is an under-served spin on SEO — but the landing leaves open how data is collected, how often audits run, and whether recommendations actually move the needle at scale.