Developer Tools●●Solid
I got tired of granting mailbox access to trigger workflows by email
GDPR-compliant email-to-webhook with per-alias payload config Mailgun lacks.
Solve My ProblemSlick
axtg
2120d ago
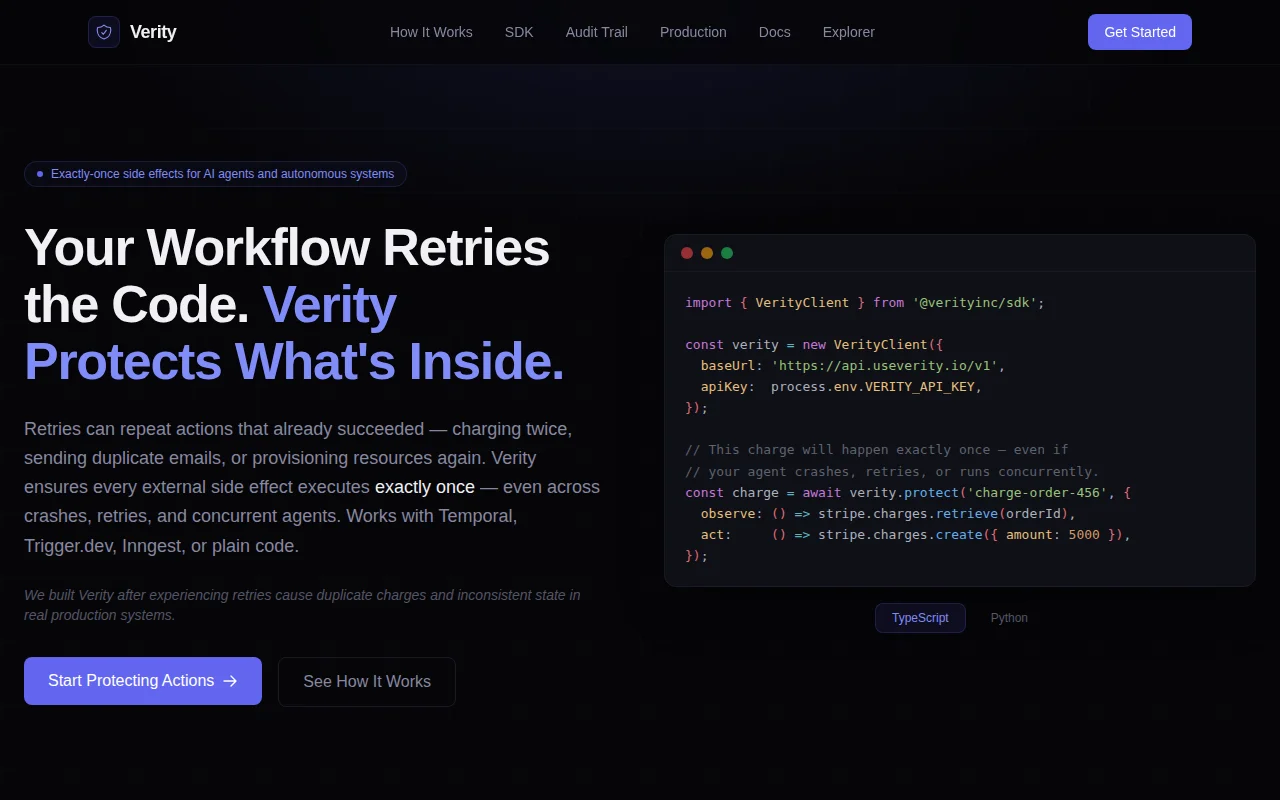
Exactly-once semantics for external APIs without replacing your workflow engine.
Backend engineers building job platforms, payments systems, and autonomous agents
Temporal · Trigger.dev · AWS Lambda with distributed transactions
I built Verity after debugging a production issue where our job platform was sending duplicate emails to tens of thousands of hotel guests.
We were running automated checkout for a chain of hotels across Germany, Spain, and New York. The process had multiple steps: validate reservations, generate folios, check guests out, send receipt emails.
The job would run for 25+ minutes processing thousands of reservations. Sometimes it would time out at 30 minutes. The platform would see the job didn't complete and restart it from the beginning.
The problem: some operations were idempotent through the provider (like creating a folio with the same ID), but others weren't (like sending emails). Guests would get duplicate receipt emails. We'd generate the same reports twice.
It took a week of adding logs to figure out what was happening. The restart was invisible to our code — it just looked like the job was running twice.
I built Verity to solve this: wrap each critical step or side effect so it's safe to restart anywhere:
// Check out guest await verity.protect(`checkout-${reservationId}`, { observe: () => hotel.getReservation(reservationId), act: () => hotel.checkout(reservationId) });
// Send receipt (not idempotent in the email service) await verity.protect(`receipt-${reservationId}`, { observe: () => checkIfEmailSent(reservationId), act: () => sendReceiptEmail(guest.email, folio) });
If the job restarts after sending the email but before finishing, the retry checks first (observe) and skips re-sending.It uses fencing tokens to prevent zombie workers from committing stale results if they wake up after being timed out. Full audit trail of what ran, what was skipped, and why.
The same pattern applies to any system that retries without human oversight — background jobs, workflow engines like Temporal, or AI agents that make autonomous decisions. If your code crashes after calling an external API, the retry needs to know what already succeeded.
Works with Temporal, Trigger.dev, plain job queues, or standalone.
Still early. Looking for people who've hit similar issues to try it and tell me what's wrong. Free for design partners.
Live: https://useverity.io Docs: https://useverity.io/docs Install: npm install @verityinc/sdk or pip install verityinc-sdk
Happy to answer questions about the design or share more war stories from that debugging week.
GDPR-compliant email-to-webhook with per-alias payload config Mailgun lacks.
Detects months-old reposted jobs before you waste time applying.
Offline job tracker is nice, but Teal and Huntr already dominate with better integrations.
Humorous rejection email analysis using Gmail API, but it's a one-off analysis, not a reusable tool.
Yet another AI job automation tool when Simplify and Teal already dominate.
Email-to-JSON with schema validation and webhook delivery, but LLM extraction isn't novel.