Developer Tools●●Solid
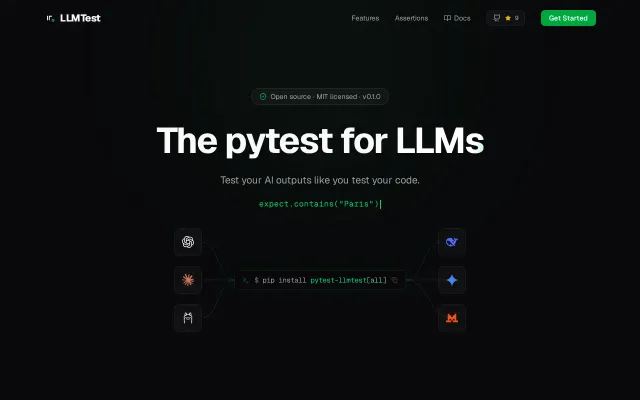
LLMTest – The pytest for LLMs with 22 built-in assertions
Pytest syntax for LLM testing avoids LLM-judge cost, but feature parity vs. LangSmith and Braintrust unproven.
Solve My ProblemSlick
furtims
403mo ago
Runtime constraint verification for AI outputs. 278 lines. Zero dependencies. Check → Score → Retry.
Lightweight retry loop that improves IFEval instruction-following from 69% to 76% accuracy.
LLM application developers, prompt engineers, AI systems requiring guaranteed output compliance
Guardrails AI · Outlines · Pydantic BaseModel validation + retry loops
The core insight: LLMs don't reliably follow instructions, but you can catch failures cheaply and retry with targeted feedback. This is essentially a lightweight "process reward model" that requires zero training.
How it works: 1. Your LLM generates output 2. ai-assert checks it against constraints (length, word count, sentence count, regex, custom predicates) 3. Each constraint returns a score in [0,1] -- composite is multiplicative (zero in any = zero overall) 4. If score < threshold, retry with feedback ("Constraint X failed because Y -- regenerate") 5. Return the best-scoring attempt
On IFEval (25 instruction-following constraint types): 69.3% -> 76.2% accuracy.
278 lines. Zero dependencies. Works with any callable that takes a string and returns a string.
pip install ai-assert
Pytest syntax for LLM testing avoids LLM-judge cost, but feature parity vs. LangSmith and Braintrust unproven.
Yet another hallucination checker when Guardrails and LMQL already cover this.
Spec compiler approach is interesting but GitHub Spec Kit and Kiro already cover this.
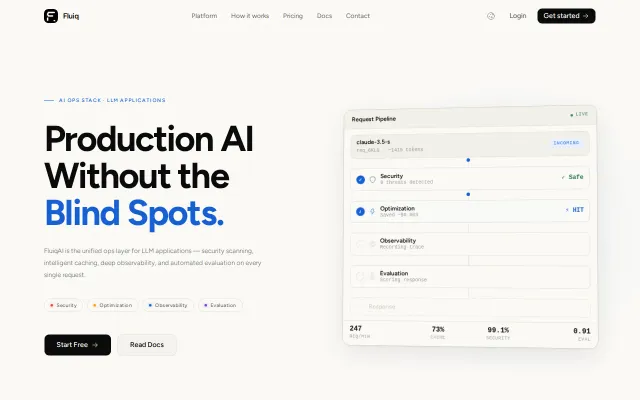
Yet another LLM ops layer when LangSmith, Helicone, and Braintrust already exist.
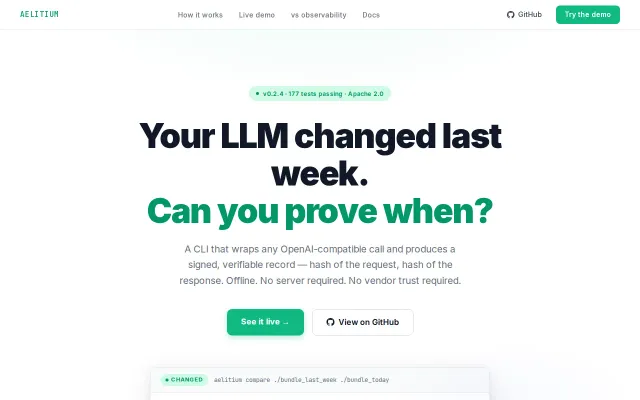
Cryptographic proof of model drift so you can audit silent OpenAI updates offline.
Deterministic verification loop makes 3.8B models match 7x larger ones for structured extraction.