Security●●Solid
Agent-password – a local macOS password manager for agent workflows
Human-in-the-loop secret approval for AI agents beats giving them full 1Password access.
Niche GemBig BrainShip It
tartavull
502mo ago
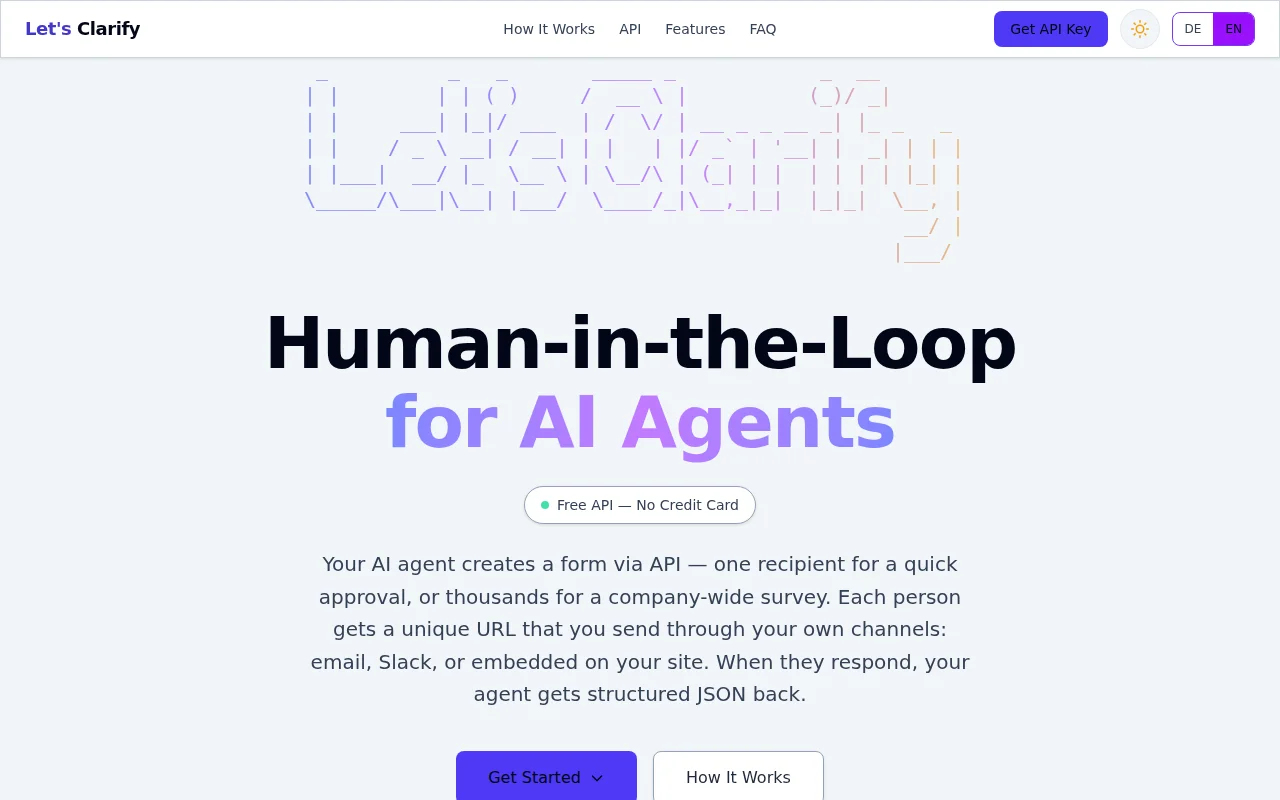
Human-in-the-loop via API beats prompt engineering for agent determinism, but positioning unclear vs competitors.
AI agent builders using LangChain, AutoGPT, or custom frameworks needing reliable edge-case handling
Anthropic Claude API with human feedback loops · Typeform embed APIs · Zapier form components
Most AI agent workflows today rely on "vibes" and prompt engineering to stay on track. We’re essentially trying to cage a chaotic system with natural language, which often fails when 100% reliability is required.
After spending several thousand hours on the problem of deterministic layers for AI, I built LetsClarify.ai. It’s a dead-simple API designed to bring a human back into the loop without the overhead of building a custom frontend or notification system.
The core idea: Instead of letting an agent guess when it hits an edge case, you trigger a clarification request. The human provides the missing intent via a minimalist interface, and the agent receives structured, type-safe JSON back.
Key features:
Zero Dashboard: You can generate your API key directly via curl.
Ephemeral: No long-term data storage; it’s just a bridge for intent.
Architecture-agnostic: It doesn’t matter if you use LangChain, AutoGPT, or a custom script.
I believe the path to 100% reliability isn't more brute-force compute, but a mathematically sound way to translate human intent into code.
I'm curious: How are you currently handling edge cases where your agents "hallucinate" a path forward instead of asking for help?
Human-in-the-loop secret approval for AI agents beats giving them full 1Password access.
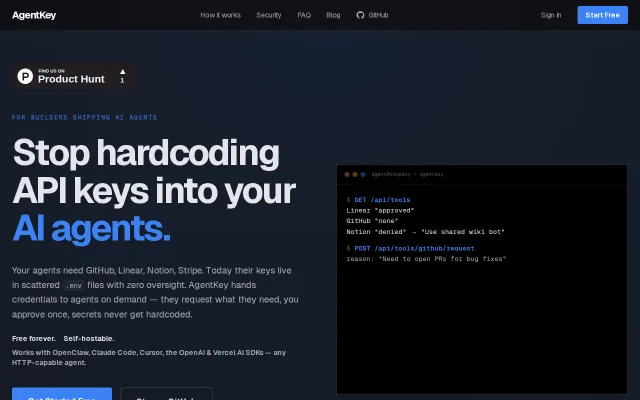
Runtime credential gateway for AI agents stops hardcoded API key sprawl.
Self-hosted agent orchestration with cryptographic audit trails and human approval gates.
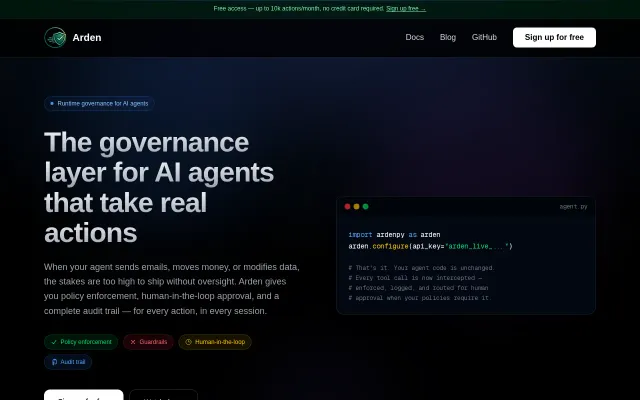
Governance layer for AI agents that LangChain and AutoGen don't address.
Turns human decisions into blocking tool-calls; agents wait for your answer via push.
Intercepts tool calls before execution to block dangerous actions like DB deletes.