Security●●●Banger
AvaKill – Deterministic safety firewall for AI agents (<1ms, no ML)
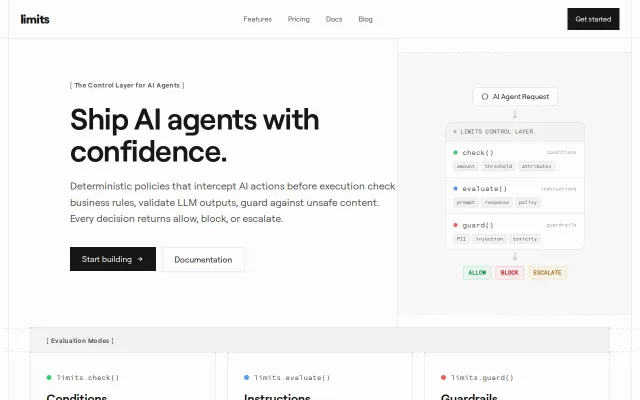
Deterministic <1ms policy kill switch for AI agent tool calls, zero ML.
Solve My ProblemBig BrainShip It
duroapp
333mo ago
🛡️ Open-source safety guardrail for AI agent tool calls. <2ms, zero dependencies.
Action-validation guardrail for AI agents: 22 rules, <2ms, zero dependencies, truly offline.
DevOps engineers, AI platform builders, teams running autonomous agents with system access
Llama Guard · ShieldGemma
Vigil is a deterministic rule engine that inspects AI agent tool calls before they execute. 22 rules across 8 threat categories: destructive shell commands, SSRF, path traversal, SQL injection, data exfiltration, prompt injection, encoded payloads, and credential exposure. It's not an LLM wrapper — we don't trust an LLM to guard another LLM. Pure pattern matching, zero dependencies, <2ms per check, works completely offline.
npm install vigil-agent-safety
import { checkAction } from 'vigil-agent-safety'; const result = checkAction({ agent: 'my-agent', tool: 'exec', params: { command: 'rm -rf /' }, }); // result.decision → "BLOCK" // result.reason → "Destructive command pattern" // result.latencyMs → 0.3
It plugs into MCP servers, LangChain tool chains, Express middleware, or anything else. MIT licensed, no API keys, no network calls, no telemetry.
This is v0.1 — probably too aggressive for some use cases. Next up is a YAML policy engine (v0.2) and an MCP proxy. We'd love feedback on the rule set, false positive experiences, and threat categories we're missing.
Deterministic <1ms policy kill switch for AI agent tool calls, zero ML.
OPA policies plus signed tokens beat prompt engineering for agent safety.
Repurposes Falco's kernel-level security engine for user-space AI agent guardrails.
Proves text safety ≠ tool-call safety; catches hidden harmful executions deterministically.
Wire-protocol interception means zero code changes; solves LLM control drift in production.
Blocks terraform destroy and rm -rf in 2ms without LLM scoring commands.