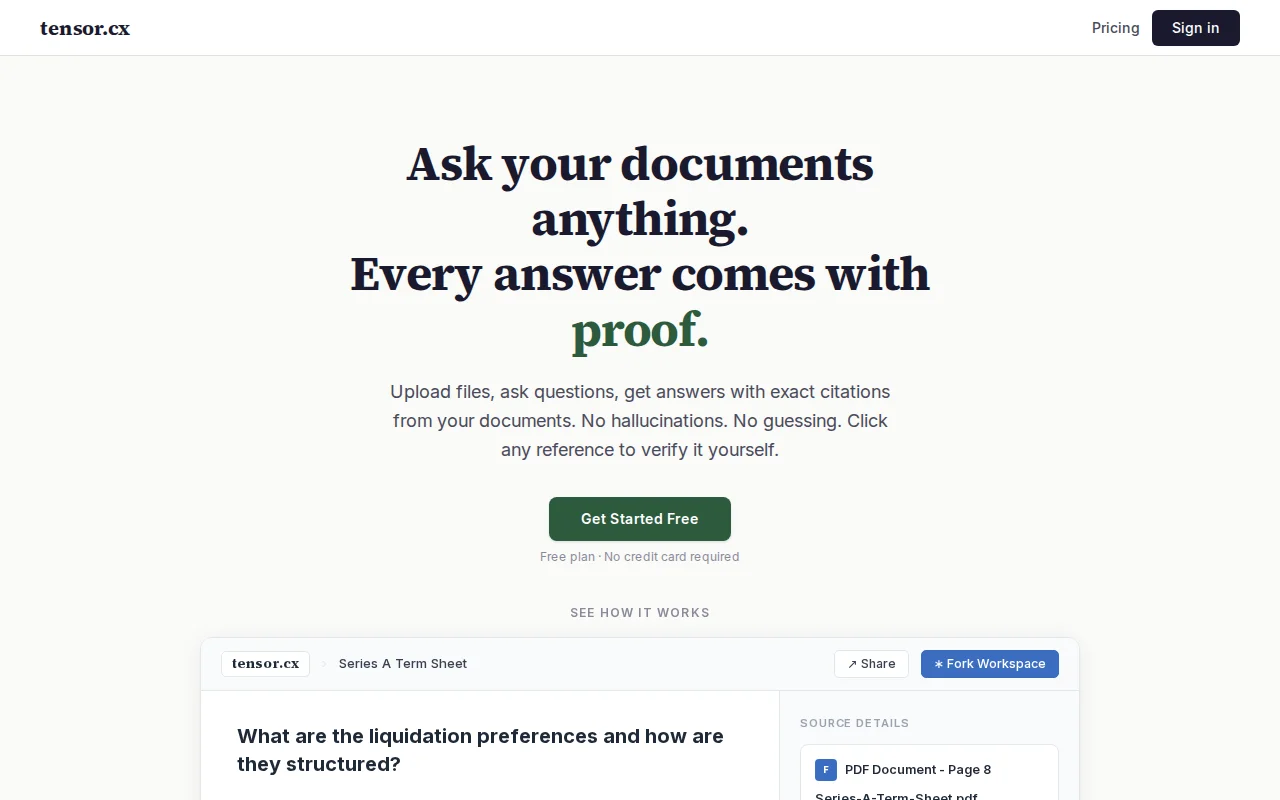
Hi HN! I built tensor.cx — a tool that turns your documents into a searchable AI knowledge base in seconds.
I built this because I kept running into the same problem: having a pile of documents (PDFs, DOCX) and needing to find specific information quickly without hallucinatory answers. Existing RAG solutions were either too complex to set up, didn't provide reliable inline citations, or made it impossible to share the actual search experience with others.
How it works:
1. Drop your files (PDF, DOCX, TXT, Markdown)
2. We chunk and embed them using OpenAI's text-embedding-3-small
3. Ask questions in natural language and get answers with exact inline citations
We give every workspace a shareable URL so you don't have to onboard your whole team just to share a document search. You just send them the link, and they can search the docs immediately. (Note: Since document uploads cost money to embed, I do require a quick login to create a workspace, but no credit card is needed for the free tier).
Live demo: https://tensor.cx
Free tier: 3 workspaces, 5 docs each, 30 queries/day.
Under the hood:
- The RAG pipeline: query -> embed -> pgvector -> top 5 chunks -> LLM (via LiteLLM) -> streamed via SSE
- Backend: Django 6 + Django Ninja, PostgreSQL, Celery
- Frontend: Next.js 16 + React 19 + Tailwind CSS 4
- Infra: Fly.io, Neon (DB), Cloudflare R2, Stripe, Clerk
I'd love to hear your feedback on the product, and I'm happy to answer any questions about the architecture, RAG pipeline, or anything else!