AI/ML●Mid
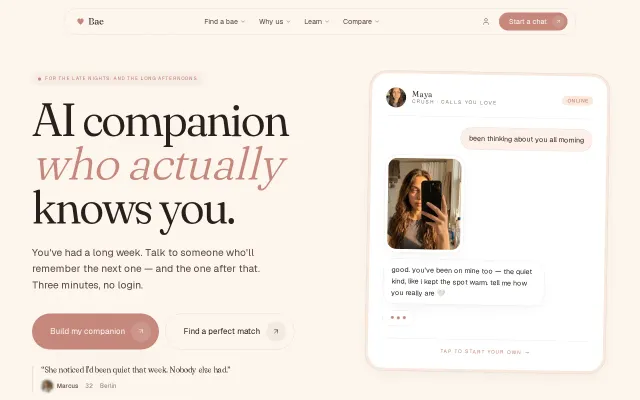
Bae – AI companion built around persistent memory architecture
Replika clone with persistent memory, but the market is already saturated.
Slick
zeshutmax
2020d ago
Git worktrees as memory backend for WhatsApp companion—genuinely novel approach to AI continuity.
Non-technical users seeking emotional support, family historians, creative writers
Replika · Woebot · Day One (diary)
I built a memory companion called Annabelle. She runs on WhatsApp and Messenger, and she's been remembering 3 people's lives for 6 months using the same git-based memory you starred. This isn't an agent framework nor running on OpenClawd, it's one specific product built on one specific idea: that the hard problem in AI isn't intelligence, it's continuity.
Here's what changed between PoC and production:
Multi-tenancy via git worktrees
The PoC was single-user. Production uses orphan branches per user, each mounted as a worktree. Memories live in structured markdown under memories/{people,contexts,events}/. Every conversation is a commit.
Four retrieval depths
The context API supports four modes: basic (most recent/frequent files), wide (semantic search across the vault), deep (complete entity files), and temporal (files plus their git log showing how things changed over time). Temporal is still the thing that makes git better than vectors for this. "How has my project evolved?" needs diff history, not cosine similarity.
What this looks like in practice
I set up a sample repo where DiffMem reads Jekyll & Hyde chapter by chapter and you can watch its understanding evolve through the commits: https://github.com/Growth-Kinetics/diffmem_sample_memory/com...
You can see what changed in the entity files, what connections it drew, what it updated. It's not a black box embedding. It's markdown and git history you can read with your eyes.
Why I built this
I have a bad memory and a genetic risk for early-onset Alzheimer's. The original goal was an entity that could remember me when I can't remember myself.
DiffMem (MIT): https://github.com/Growth-Kinetics/DiffMem
Sample memory: https://github.com/Growth-Kinetics/diffmem_sample_memory
Annabelle: https://withanna.io
Replika clone with persistent memory, but the market is already saturated.
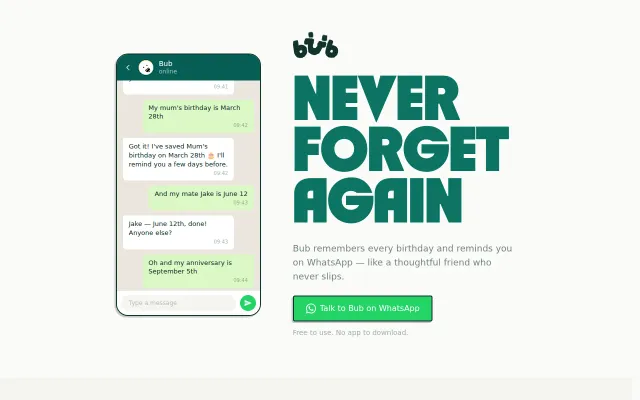
WhatsApp-native birthday tracker beats another standalone app you will never open.
Git-backed messaging in one HTML file, but public repos mean public messages.
WhatsApp AI and Hindi voice, but multi-persona debate already saturated (Claude Projects, OpenAI's beta).
Live2D companion with memory, but solves a niche problem atop Open-LLM-VTuber.
WhatsApp automotive dispatch for Kenya, but Uber-like competition and geographic limits hurt scalability.