AI/ML●●Solid
AI/ML benchmark for local LLM inference and XGBoost training on GPU/CPU
One-command benchmark suite comparing Ollama and XGBoost performance with a shared Streamlit dashboard.
Solve My ProblemNiche Gem
albedan
202mo ago
CPU-only LLM inference via vGPU SIMD, but prototype status and deployment clarity unclear.
Researchers, cost-sensitive ML ops, regions with GPU scarcity
llama.cpp · ONNX Runtime · Groq
I’m Padam, a developer based in Dubai.
Over the last 2 years I’ve been experimenting with the idea that AI inference might not require GPUs.
Modern LLM inference is often memory-bound rather than compute-bound, so I built an experimental system that virtualizes GPU-style parallelism from CPU cores using SIMD vectorization and quantization.
The result is AlifZetta — a prototype AI-native OS that runs inference without GPU hardware.
Some details:
• ~67k lines of Rust • kernel-level SIMD scheduling • INT4 quantization • sparse attention acceleration • speculative decoding • 6 AI models (text, code, medical, image,research,local)
Goal: make AI infrastructure cheaper and accessible where GPUs are expensive.
beta link is here: https://ask.axz.si
Curious what HN thinks about this approach.
One-command benchmark suite comparing Ollama and XGBoost performance with a shared Streamlit dashboard.
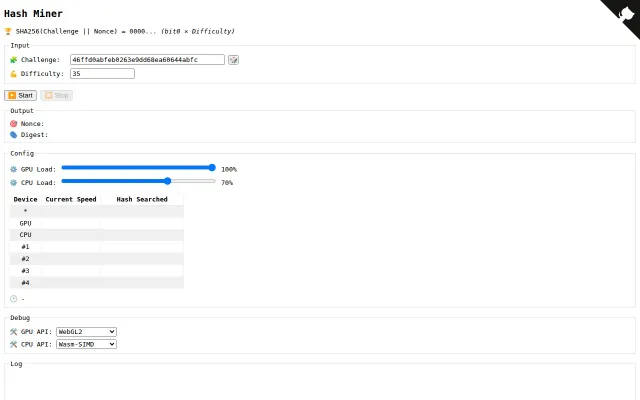
WebGPU and WASM-SIMD hash mining in browser with per-device load controls.
NumPy API on WebGPU with zero shader writing beats TensorFlow.js bloat for compute.
Monitors GPU+CPU+memory in one themed terminal view—leaner than Glances.
Granular API key controls and token cost tracking beat basic llama.cpp wrappers.
28% faster Vulkan-to-CUDA on Qwen, but llm.c and llama.cpp already own inference.