AI/ML●●●Banger
Run 500B+ Parameter LLMs Locally on a Mac Mini
1.58-bit quantization + layer streaming shrinks 144GB models to 36GB, runs on Mac Mini.
WizardryZero to OneBig Brain
fatihturker
17103mo ago
Ternary quantization and layer streaming for 140B models on Mac Mini, but claims lack real-world validation.
ML researchers and Apple Silicon users experimenting with large model inference on consumer hardware
llama.cpp · GPTQ quantization · Ollama
I built OpenGraviton, an open-source AI inference engine designed to push the limits of running extremely large models on consumer hardware.
The system combines several techniques to drastically reduce memory and compute requirements:
• 1.58-bit ternary quantization ({-1, 0, +1}) for ~10x compression • dynamic sparsity with Top-K pruning and MoE routing • mmap-based layer streaming to load weights directly from NVMe SSDs • speculative decoding to improve generation throughput
These allow models far larger than system RAM to run locally.
In early benchmarks, OpenGraviton reduced TinyLlama-1.1B from ~2.05GB (FP16) to ~0.24GB using ternary quantization. Synthetic stress tests at the 140B scale show that models which would normally require ~280GB FP16 can fit within ~35GB when packed with the ternary format.
The project is optimized for Apple Silicon and currently uses custom Metal + C++ tensor unpacking.
Benchmarks, architecture, and details: https://opengraviton.github.io
GitHub: https://github.com/opengraviton
1.58-bit quantization + layer streaming shrinks 144GB models to 36GB, runs on Mac Mini.
Native ternary training beats post-training quantization for memory efficiency.
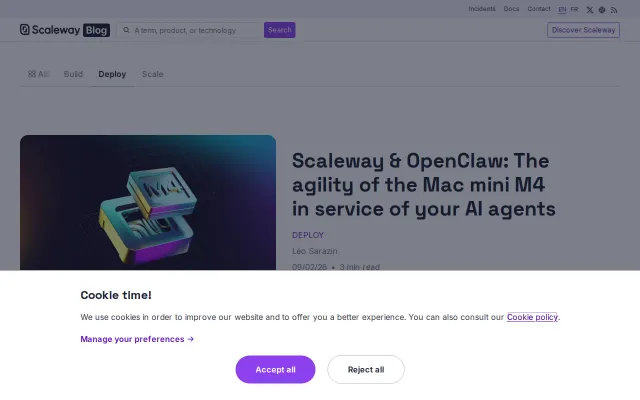
Shows how to run OpenClaw agents on a rented Mac mini M4 and use the 38 TOPS Neural Engine for low-latency local inference while offloading heavy work to Scaleway's Generative APIs. Practical details — hourly billing, remote desktop access, and step-by-step tutorials — make it useful for PoCs, but it's essentially a cloud-provider integration rather than a new agent platform.
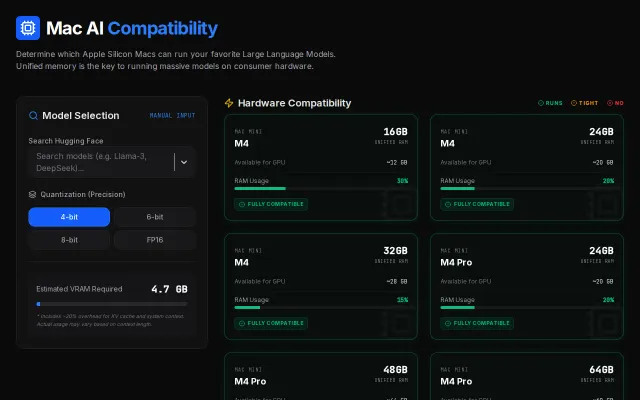
Clean hardware-model compatibility checker, but solves a narrow, one-time lookup problem.
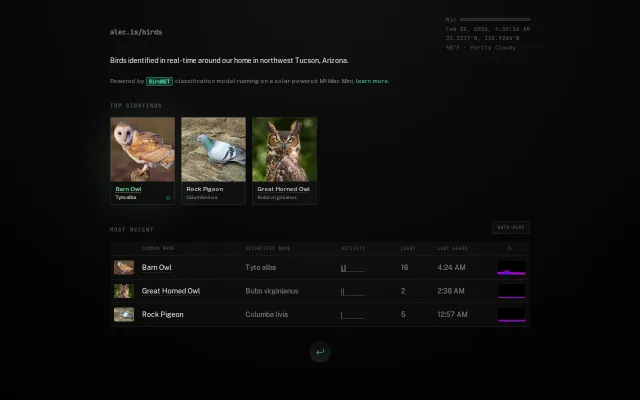
Solar-powered local bird AI is charming, but the tech (BirdNET + local inference) is established.
Streams LLM weights from CD-ROM during inference to fit 77MB models in 32MB RAM.